word为什么会切到字

Word为什么会切到字
问题描述
在使用Microsoft Word时,有时候会遇到一个问题,即在输入文字时,光标会自动跳到下一个字符的位置,而不是停留在当前位置,这个问题被称为“切到字”。
原因分析
1、自动换行:当输入的文字超过一行的宽度时,Word会自动将文字换行,这时,光标会跳到下一行的开头,而不是继续留在当前行的末尾。
2、空格和回车:在输入文字时,如果按下空格键或回车键,光标会跳到下一个字符的位置,这是因为空格和回车被视为分隔符,用于分隔不同的单词或段落。
3、自动纠错:Word具有自动纠错功能,可以检测并纠正拼写错误、语法错误等,当Word检测到可能的错误时,光标会跳到错误的部分,以便进行修正。
4、快捷键操作:在使用Word时,可能会使用一些快捷键来执行特定的操作,如复制、粘贴、撤销等,这些快捷键操作可能会导致光标的移动。
解决方法
1、取消自动换行:在Word的“页面布局”选项卡中,找到“段落”组,点击“显示/隐藏格式”按钮,取消选中“自动换行”选项,这样,即使输入的文字超过一行的宽度,也不会自动换行。
2、使用软回车:在需要换行的地方,可以使用软回车(Shift + Enter)代替硬回车(Enter),软回车不会使光标跳到下一行的开头,而是在同一行的末尾。
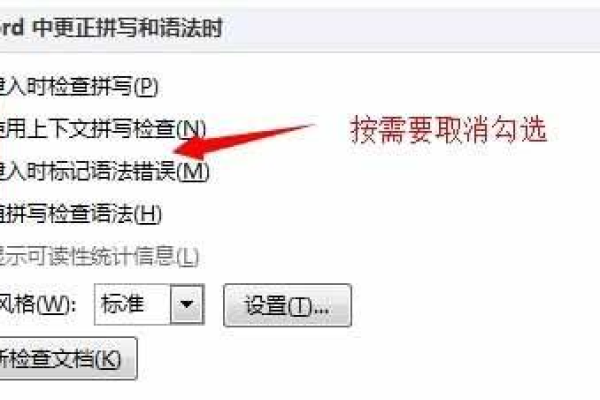
3、关闭自动纠错:在Word的“文件”选项卡中,找到“选项”,点击“校对”选项卡,取消选中“在输入时检查拼写和语法”选项,这样,Word就不会在输入时自动纠错,导致光标移动。
4、避免使用快捷键:尽量避免使用快捷键操作,特别是在输入文字时,如果需要使用快捷键,可以先停止输入,再执行相应的操作。
归纳
Word切到字的问题通常是由于自动换行、空格和回车、自动纠错以及快捷键操作等原因导致的,通过取消自动换行、使用软回车、关闭自动纠错和避免使用快捷键等方法,可以解决这一问题。