
上一篇
什么是CDN建模,它在网络性能优化中扮演了什么角色?
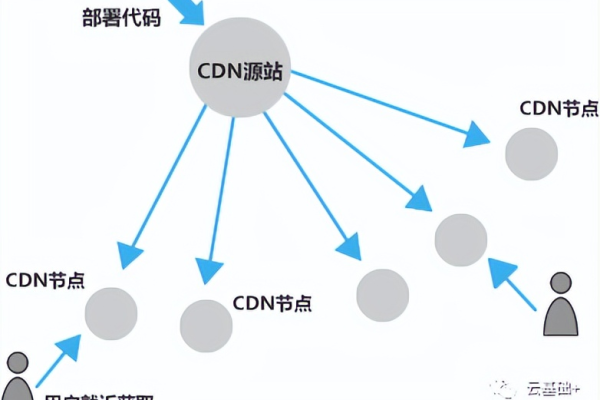
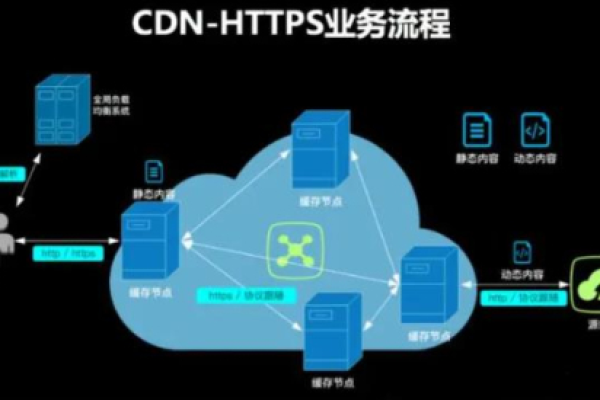
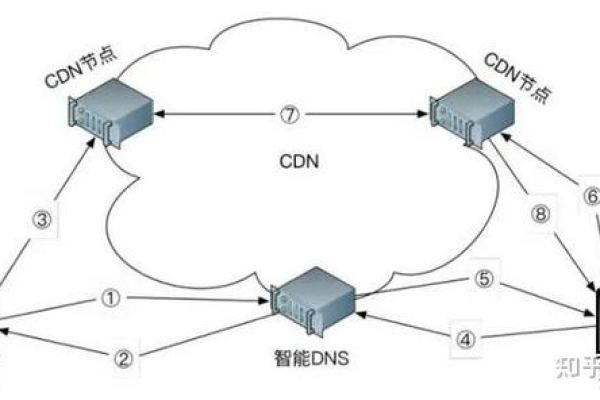
由于没有提供具体的上下文或内容,我将提供一个通用的38字回答。如果您有特定主题或内容需要帮助,请提供相关信息。,, cdn建模是利用内容分发网络技术,通过在多个地理位置分布的服务器上缓存和传输数据,以加快网页加载速度、减轻源站压力并提高网站可靠性的一种技术手段。
CDN建模是一个复杂且系统的过程,涉及多个关键步骤,以下是关于CDN建模的详细解答:

一、数据收集
1、数据来源:
CDN运营数据通常来自多个渠道,如服务器日志、监控系统、用户反馈等,整合这些数据可以提供全面的视角,有助于全面分析和建模。
2、数据种类:
常见的数据种类包括流量数据、缓存命中率、响应时间、错误率等,这些数据各自有不同的特点和用途,全面收集这些数据有助于模型的精确构建。
3、数据校验:
为了确保数据的准确性,需要建立严格的数据校验机制,常见的校验方法包括数据格式校验、数据范围校验、逻辑校验等,通过这些校验,可以过滤掉不合规的数据点,确保数据的准确性。
二、数据清洗
数据清洗是指对收集到的数据进行处理,去除噪音数据和异常数据,确保数据的质量和一致性,数据清洗的步骤包括缺失值处理、重复值处理、异常值处理等。
缺失值处理:删除含有缺失值的记录、用均值或中位数填补缺失值、用插值法填补缺失值等。
重复值处理:删除重复值、合并重复值等。
异常值处理:删除异常值、用均值或中位数替换异常值、用插值法替换异常值等。
三、特征工程
特征工程是指对数据进行转换和处理,以提取出对模型有用的特征,特征工程的步骤包括特征选择、特征提取、特征转换等。
特征选择:从原始数据中选择出对模型有用的特征,常见的特征选择方法包括过滤法、包裹法、嵌入法等。
特征提取:从原始数据中提取出新的特征,常见的特征提取方法包括主成分分析、线性判别分析、独立成分分析等。
特征转换:对原始特征进行转换,以提高模型的性能,常见的特征转换方法包括标准化、归一化、编码等。
四、模型选择
模型选择是指选择合适的机器学习模型进行训练和预测,常见的模型包括回归模型、分类模型、聚类模型等。
回归模型:用于预测连续变量的模型,如线性回归、岭回归、Lasso回归等。
分类模型:用于预测离散变量的模型,如逻辑回归、决策树、随机森林、支持向量机等。
聚类模型:用于将数据分成多个簇的模型,如K均值聚类、层次聚类、DBSCAN等。
五、模型评估
模型评估是指对模型的性能进行评估,以确定模型的好坏,常见的评估指标包括准确率、召回率、F1值、均方误差等。
准确率:预测正确的样本数占总样本数的比例,准确率越高,模型的性能越好。
召回率:预测正确的正样本数占所有正样本数的比例,召回率越高,模型的性能越好。
F1值:准确率和召回率的调和平均值,F1值越高,模型的性能越好。
均方误差:预测值与真实值之间的误差的平方和的平均值,均方误差越小,模型的性能越好。
六、项目团队管理系统的使用
在进行CDN运营数据建模时,项目团队管理系统可以大大提高工作效率和团队协作能力,这里推荐两个系统:研发项目管理系统PingCode和通用项目协作软件Worktile。
PingCode:专为研发团队设计的项目管理系统,提供了丰富的功能,如需求管理、任务管理、缺陷管理、版本管理等,通过PingCode,团队成员可以高效地协作,跟踪项目进度,提高工作效率。
Worktile:通用的项目协作软件,适用于各种类型的团队,它提供了任务管理、时间管理、文档管理、沟通工具等功能,可以帮助团队成员高效地协作,顺利完成项目。
CDN建模是一个涉及多个关键步骤的复杂过程,包括数据收集、数据清洗、特征工程、模型选择、模型评估以及项目团队管理系统的使用,在实际操作中,需要根据具体情况选择合适的方法和工具,以确保模型的准确性和有效性。
以上内容就是解答有关“cdn建模”的详细内容了,我相信这篇文章可以为您解决一些疑惑,有任何问题欢迎留言反馈,谢谢阅读。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/15793.html
相关文章
-
什么是CDN TTFB?它在网络性能中扮演什么角色?
-
谁是CDN战神,他/她在网络世界中扮演了什么角色?
-
什么是负载均衡门限,它在网络优化中扮演什么角色?
-

CIDR是什么?它在网络管理中扮演了什么角色?
-
什么是CDN NS,它在网络架构中扮演什么角色?
-
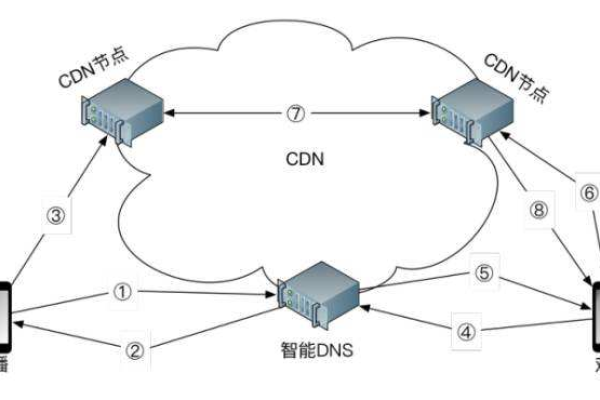
什么是CDN形式,它在网络技术中扮演什么角色?
-
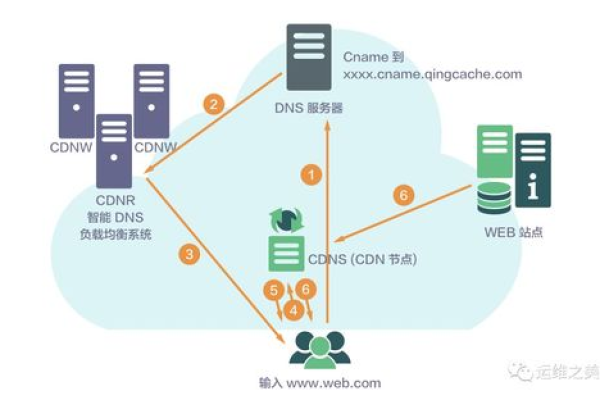
什么是CDN中心,它在网络架构中扮演什么角色?
-
什么是CDN设备,它在网络中扮演什么角色?
-
什么是CDN靶机,它在网络安全中扮演什么角色?
-
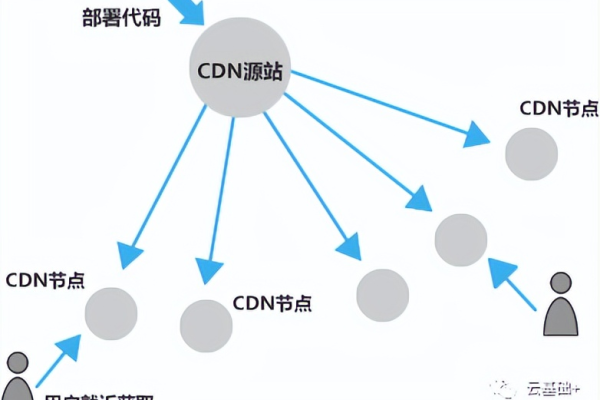
什么是CDN回源,它在网络技术中扮演什么角色?
-
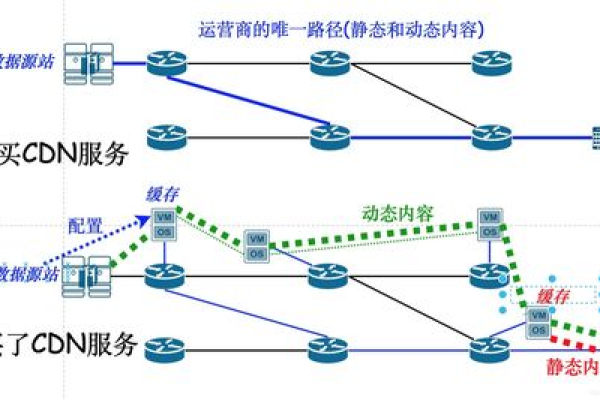
什么是CDN报头,它在网络传输中扮演什么角色?
-
MySQL预编译与编译,它们在数据库性能优化中扮演什么角色?
-

什么是CDN中介?它在网络传输中扮演什么角色?
-
什么是CDN按键?它在网络技术中扮演什么角色?
-

什么是CDN编码?它在网络传输中扮演什么角色?
-
什么是CDN板?它在网络加速中扮演什么角色?
-
什么是CDN单元?它在网络中扮演什么角色?
-
什么是CDN机?它在网络中扮演什么角色?
-
什么是CDN Gate?它在网络中扮演什么角色?
-
什么是CDN子网?它在网络架构中扮演什么角色?