上一篇
如何有效利用robots协议来优化网站爬虫行为?
Robots协议(也称为robots.txt)是一种网站管理员用来指示网络机器人(如搜索引擎爬虫)哪些页面或文件不应被访问的文本文件。它位于网站的根目录下,通过特定的语法规则告诉爬虫程序哪些内容可以抓取,哪些应避免。
【robots协议】
Robots协议,全称为“网络爬虫排除标准”(Robots Exclusion Protocol),是互联网上用于指导搜索引擎蜘蛛如何抓取和访问网站的一种协议,通过Robots协议,网站可以告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,从而保护敏感信息和数据,确保用户隐私不被侵犯,本文将对Robots协议的作用、语法和最佳实践进行深入探讨,并介绍如何在Python爬虫中遵守Robots协议。
Robots协议的主要作用是规范搜索引擎蜘蛛的行为,使其在抓取网站内容时遵循一定的规则,这有助于防止搜索引擎抓取到网站的敏感信息,如后台管理页面、用户个人信息等,Robots协议还可以减轻服务器压力,因为限制了蜘蛛的访问范围,从而降低了服务器的资源消耗。
Robots协议的语法相对简单,主要包括Useragent、Disallow和Allow三个指令,Useragent指定了适用的搜索引擎类型,如百度蜘蛛、谷歌蜘蛛等;Disallow表示禁止访问的路径;Allow表示允许访问的路径,通过组合使用这些指令,网站管理员可以实现对搜索引擎蜘蛛的精确控制。
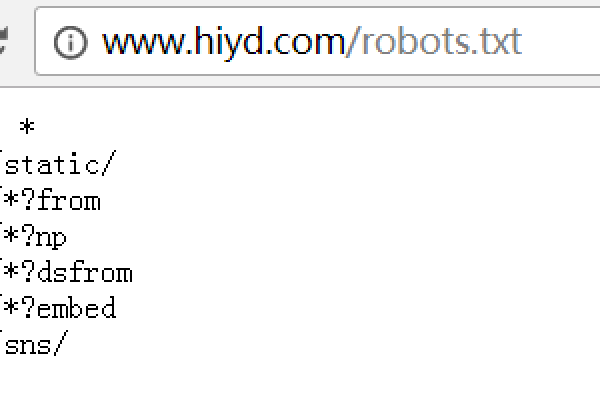
在实际应用中,网站管理员需要在网站根目录下创建一个名为robots.txt的文件,并在其中编写相应的指令,如果要禁止所有搜索引擎抓取网站的某个目录,可以在robots.txt文件中添加如下内容:
Useragent: * Disallow: /private/
这意味着所有搜索引擎都被禁止访问名为“private”的目录,需要注意的是,robots.txt文件的编写应遵循一定的格式要求,以确保其有效性和可读性。
除了基本的语法外,还有一些高级用法可以帮助网站管理员更灵活地控制搜索引擎的访问权限,可以使用通配符*来匹配任意字符,或使用$来匹配URL的结束字符,还可以利用Crawldelay指令来设置搜索引擎抓取页面的时间间隔,以降低服务器负载。
在Python爬虫中遵守Robots协议是非常重要的,需要检查目标网站的robots.txt文件,了解允许和禁止访问的范围,根据这些规则来调整爬虫的抓取策略,确保不违反网站的规定,可以通过以下步骤来实现:
1、获取目标网站的robots.txt文件的URL(通常是将网站域名与/robots.txt拼接而成)。
2、使用Python的requests库发送HTTP请求,获取robots.txt文件的内容。
3、解析robots.txt文件的内容,提取出Useragent、Disallow和Allow等指令。
4、根据提取出的指令来调整爬虫的抓取策略,确保只访问允许访问的路径。
通过以上步骤,可以在Python爬虫中有效地遵守Robots协议,既保护了网站的利益,又避免了因违规抓取而导致的法律风险。
Robots协议在互联网中扮演着重要的角色,它为网站管理员提供了一种简单而有效的方法来控制搜索引擎的抓取行为,通过合理地编写和使用robots.txt文件,可以保护网站的敏感信息,降低服务器压力,并提高搜索引擎的抓取效率,在进行网络爬虫开发时,遵守Robots协议也是一项基本的道德准则和技术要求,深入了解并正确应用Robots协议对于网站管理员和爬虫开发者来说都是至关重要的。
相关问答FAQs:
Q1: 如果网站没有robots.txt文件,是否意味着搜索引擎可以随意抓取?
A1: 是的,如果网站没有robots.txt文件,搜索引擎通常会默认该网站允许所有页面被抓取,但需要注意的是,即使没有robots.txt文件,网站管理员仍可以通过其他手段(如meta标签或HTTP响应头)来限制搜索引擎的访问权限。
Q2: 遵守Robots协议是否意味着爬虫不会侵犯网站的版权?
A2: 遵守Robots协议主要是尊重网站的抓取规则,避免抓取到禁止访问的内容,但关于版权问题,还需要根据具体的法律法规和网站规定来判断,如果网站明确声明了某些内容的版权归属和授权范围,那么在使用这些内容时还需要遵循相应的版权规定。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/153560.html