strip函数是什么?

Python的strip()函数是一个非常实用的字符串处理方法,它主要用于去除字符串两端的指定字符(默认为空格),这个函数在处理用户输入、数据清洗以及编程中的文本数据处理时非常常用,以下是对strip()函数的详细解释和示例:
一、strip()函数的基本用法
1、语法:str.strip([chars])
2、参数:
str:要进行操作的字符串。
chars(可选):指定要删除的字符集合(字符串),如果未提供此参数,默认会去除所有空白字符(包括空格、制表符、换行符等)。
3、返回值:返回一个新字符串,该字符串是原始字符串去除前导和尾随字符后的结果。
二、示例与详解
| 示例 | 说明 |
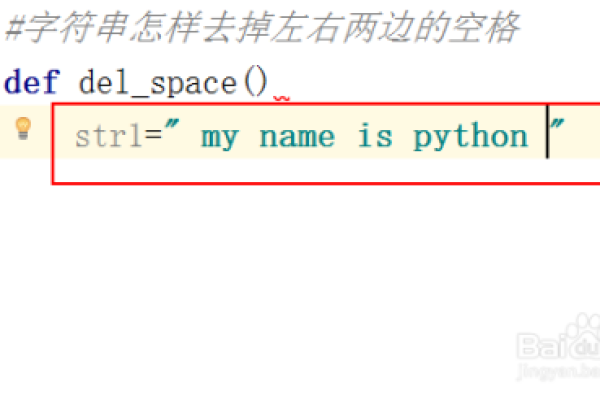
s = " hello world "result = s.strip()print(result) |
输出:”hello world” 解释:去除字符串两侧的空格。 |
s = "---hello world---"result = s.strip("-")print(result) |
输出:”hello world” 解释:去除字符串两侧的连字符(-)。 |
text = ">>>Python |
输出:"Python" 解释:去除字符串两侧的尖括号(>和 |
price = "$$99.99$$"cleaned_price = price.strip("$")print(cleaned_price) |
输出:"99.99" 解释:去除字符串两侧的美元符号($)。 |
text = "strip STRIP StRiP"cleaned_text = text.lower().strip("strip")print(cleaned_text) |
输出:"" 解释:先将所有字符转换为小写,然后去除字符串两侧的“strip”字符序列,由于整个字符串都由这些字符组成,所以结果为空字符串。 |
| `text = "Python
striptExample"<br>cleaned_text = text.strip("
t")<br>print(cleaned_text)` | 输出:"Python strip Example"<br>解释:去除字符串两侧的换行符和制表符。 |
三、strip()函数与其他相关函数的比较
lstrip():仅去除字符串左侧的字符。
rstrip():仅去除字符串右侧的字符。
strip():去除字符串两侧的字符。
四、注意事项
1、strip()函数只能去除字符串两端的指定字符,不能去除字符串中间的字符。
2、如果指定的字符不在字符串的两端,则不会对字符串做任何改变。
3、Python的字符串是不可变的,因此strip()函数不会修改原始字符串,而是返回一个新的字符串。
五、FAQs
Q1: strip()函数可以去除哪些字符?
A1: strip()函数默认可以去除所有的空白字符(包括空格、制表符、换行符等),如果提供了chars参数,则可以去除chars中指定的字符。
Q2: 如何使用strip()函数去除字符串两侧的所有非数字字符?
A2: 可以使用正则表达式结合strip()函数来实现这一需求。
import re
s = "abc123def"
cleaned_s = re.sub('D', '', s)
print(cleaned_s) # 输出:123
在这个例子中,我们使用了正则表达式D来匹配所有非数字字符,并将其替换为空字符串,从而只保留数字部分。
六、小编有话说
strip()函数作为Python中处理字符串的一个基础工具,其简洁而强大的功能使得它在数据处理中扮演着重要角色,无论是清理用户输入还是处理外部数据源,strip()都能帮助我们快速去除不必要的字符,提高数据的质量和代码的可读性,希望本文的介绍能帮助大家更好地理解和使用strip()函数。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22