
上一篇
如何在MongoDB中使用MapReduce进行高效的数据处理?
MongoDB 的 MapReduce 是一种数据处理范式,允许在服务器端处理大量数据。它由两个函数组成:一个映射(map)函数,用于将文档转换成键值对;和一个归约(reduce)函数,用于合并这些键值对。MapReduce 特别适用于复杂的聚合任务和大规模数据集分析。
深入理解MongoDB中的MapReduce功能

MongoDB作为一种广泛使用的非关系型数据库,其强大的数据处理能力使其在大数据和实时应用场景中表现出色,MapReduce是一种高效的数据处理模型,它允许用户对大规模数据集执行复杂的数据分析操作。
1、MapReduce的基本概念
MapReduce的核心思想是将一个大问题分解为多个小问题(Map阶段),然后再将各个小问题的解决方案合并起来,形成大问题的解决方案(Reduce阶段),在MongoDB中,MapReduce通过两个主要函数实现:map函数和reduce函数,Map函数负责从集合中的每个文档生成一个或多个键值对;而reduce函数则负责接收具有相同键的值集合,并对其进行处理以产生单一的输出值。
2、MapReduce的执行流程
Map阶段:在这个阶段,系统遍历集合中的每个文档,并对每个文档应用map函数,map函数的输出是一系列的键值对,这些键值对被用作下一阶段——Shuffle阶段的输入。
Shuffle阶段:这一阶段的主要任务是根据键来分组map阶段的输出结果,系统会为每个唯一的键创建一个列表,该列表包含了该键下的所有值。
Reduce阶段:在这一阶段,系统会调用reduce函数,该函数接收两个参数:一个是键,另一个是该键对应的值列表,reduce函数的目的是将这些值合并成一个单一的值。
Finalize阶段:这是可选的阶段,用于在最终结果被输出之前进行一些额外的处理或数据“修剪”。
3、MapReduce的语法和选项
MongoDB中执行MapReduce操作的基本语法如下:
“`
db.collection.mapReduce(
mapFunction,
reduceFunction,
{
out: collection,
query: document,
sort: document,
limit: number
}
)
“`
mapFunction和reduceFunction是必需的,分别代表map函数和reduce函数的实现,还有几个可选的参数,例如out指定输出集合的名称,query指定选取哪些文档作为MapReduce操作的输入,sort指定输入文档的排序方式,而limit则限制输入文档的数量。
4、MapReduce的高级应用
对于需要处理的数据量极大的场景,MapReduce能够显著提高处理效率,在大数据分析中,可以利用MapReduce来进行复杂的数据聚合、统计分析等,由于MongoDB支持分布式环境,MapReduce可以很容易地扩展到多台服务器上,从而处理海量的数据集。
通过以上分析,可以看出MongoDB中的MapReduce不仅提供了一种高效处理和分析大数据的方法,还因其灵活性和强大的功能在各种应用场景中显示出巨大的潜力,接下来将在FAQs部分回答关于MongoDB MapReduce的一些常见问题,以帮助读者更好地理解和使用这一功能。
相关问答FAQs:
如何选择合适的MapReduce操作中的key?
答:选择MapReduce操作中的key很关键,因为它决定了数据如何分组以及reduce函数的调用次数,应该选择一个可以最大限度地减少数据处理量和计算复杂性的键,如果要统计每种类型的文档数量,可以将文档类型作为键。
MapReduce操作中的性能优化有哪些建议?
答:为了优化MapReduce操作的性能,可以考虑以下几点:尽量减少map函数输出的数据量;合理设计reduce函数以提高效率;考虑使用索引来加速查询操作,特别是在处理大型集合时。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/149275.html
相关文章

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
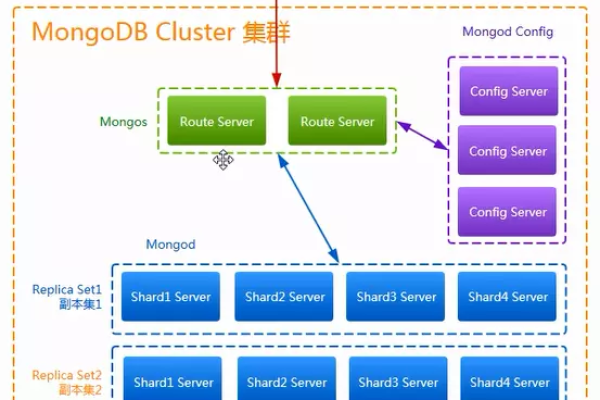
如何在MongoDB中使用MapReduce进行高效的并行数据处理和导入?
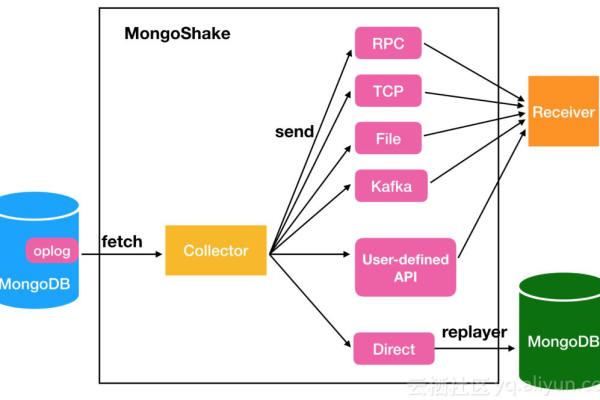
如何在MongoDB中安装并使用MapReduce进行数据处理?
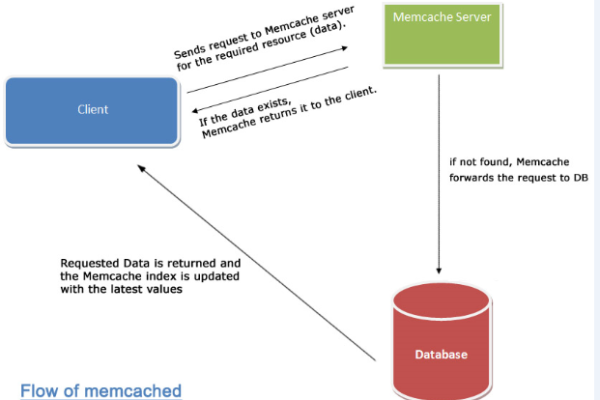
如何在MongoDB中使用MapReduce和JavaScript优化页面数据处理?
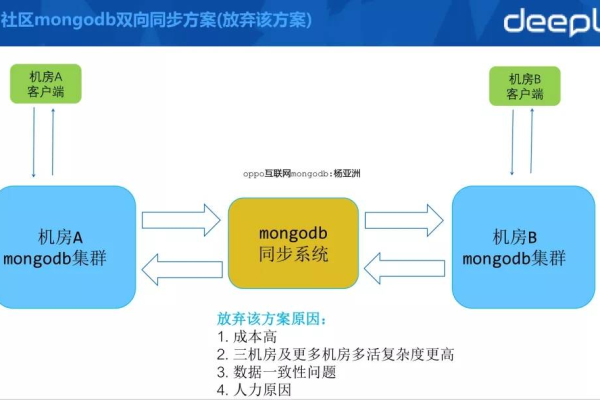
如何使用MongoDB中的MapReduce进行复杂数据处理和聚合?
如何在MongoDB中使用MapReduce进行去重操作?
Morphia MapReduce: 如何有效使用MongoDB的MapReduce功能?
如何使用MongoDB MapReduce功能进行高级数据处理?








