开发一个b2c网站所需要_步骤四:搭建网站

开发一个B2C网站是一个复杂的过程,涉及多个步骤,以下是关于搭建网站这一步骤的详细指南:
1. 选择网站构建平台
你需要选择一个适合你业务需求的网站建设平台,这可以是开源解决方案如WordPress、Magento或者专业的电子商务平台如Shopify和WooCommerce,每个平台都有其特点和适用场景,因此选择时要考虑易用性、扩展性、成本和支持等因素。
2. 购买域名和托管服务
域名注册:选择一个简短、易于记忆且与你的品牌相关的域名。
托管服务:根据你的预算和需求选择合适的托管服务,包括共享托管、VPS或专用服务器。
3. 设计网站结构
规划网站的页面结构和导航菜单,确保用户能够轻松找到他们想要的产品或信息,常见的页面包括首页、产品目录、购物车、结算页面和联系我们页面等。
4. 设计用户界面(UI)和用户体验(UX)
UI设计:确保网站的颜色方案、字体和布局符合品牌形象,同时提供良好的视觉体验。
UX设计:优化网站的交互设计,确保用户可以轻松地浏览和购买产品。
5. 开发网站功能
产品展示:开发产品列表和详情页面,包括高质量的图片和详细的描述。
购物车系统:实现添加、修改和删除购物车中商品的功能。
支付系统集成:集成安全的支付网关,如PayPal、Stripe或支付宝。
订单管理:开发后台订单管理系统,便于跟踪和处理客户订单。
客户支持:设置客户服务系统,如在线聊天支持或FAQ页面。
6. 搜索引擎优化(SEO)
关键词优化:研究并应用目标关键词以提高搜索引擎排名。
元数据优化标签、描述标签和alt文本。
内容营销:创建高质量的博客文章和产品描述以吸引搜索引擎的关注。
7. 测试网站
功能测试:确保所有链接和按钮正常工作,页面加载速度快。
兼容性测试:确保网站在不同浏览器和设备上都能正常显示。
安全性测试:检查潜在的安全破绽,确保客户数据的安全。
8. 发布和维护
网站发布:一旦测试完成,你可以将网站正式发布到互联网上。
持续维护:定期更新内容,修复发现的问题,并根据用户反馈进行改进。
9. 营销推广
社交媒体营销:利用社交媒体平台推广你的B2C网站。
电子邮件营销:建立邮件列表,发送定期的产品更新和优惠信息。
付费广告:考虑使用Google AdWords或Facebook Ads来吸引更多访问者。
单元表格:关键任务与时间线
| 任务 | 负责人 | 预计时间 |
| 选择网站构建平台 | IT团队 | 1周 |
| 购买域名和托管服务 | IT团队 | 1周 |
| 设计网站结构 | UI/UX设计师 | 2周 |
| 设计UI/UX | UI/UX设计师 | 3周 |
| 开发网站功能 | 开发人员 | 68周 |
| SEO优化 | 营销团队 | 持续进行 |
| 测试网站 | QA团队 | 2周 |
| 发布网站 | IT团队 | 1天 |
| 维护和更新 | IT团队 | 持续进行 |
| 营销推广 | 营销团队 | 持续进行 |
步骤和时间表仅供参考,实际项目可能会根据特定需求和条件进行调整,开发B2C网站是一个迭代过程,需要不断地测试、评估和优化以满足最终用户的需求。




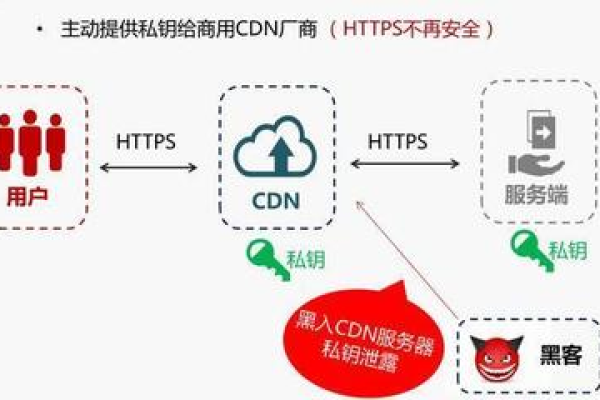
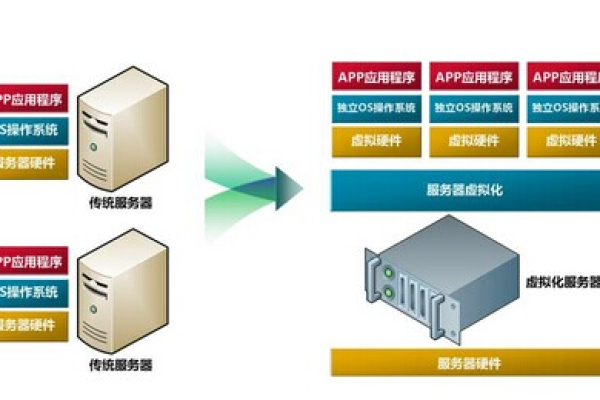

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22