双十一海外云服务器抢购攻略,如何抓住最佳优惠时机?

双十一海外云服务器,指的是在每年的11月11日,也就是中国的”光棍节”期间,许多海外云服务提供商会推出各种优惠活动,以吸引用户购买他们的云服务器服务。
双十一海外云服务器选购指南提供了全面的指导和建议,以下是对双十一海外云服务器的详细分析:
1、基本知识
定义:海外云服务器是利用虚拟化技术将传统物理服务器资源整合,以云服务形式提供给用户,主要服务于国外用户。
特点:具备高灵活性、强大的可扩展性和稳定性,适合不同规模的需求从个人到企业级应用。
2、需求明确
个人使用:对于搭建个人网站或存储文件等轻量级需求,可以考虑成本较低的供应商如DigitalOcean和Vultr。
企业需求:需要更高的稳定性和安全性,推荐选择大型云服务商如AWS、Azure和Google Cloud,它们提供弹性扩展、全球基础设施支持等高级功能。
3、供应商选择
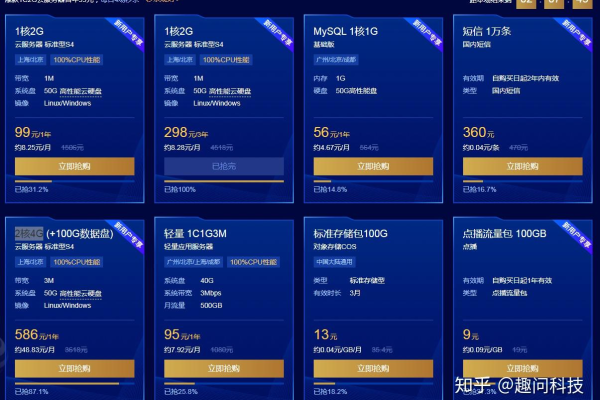
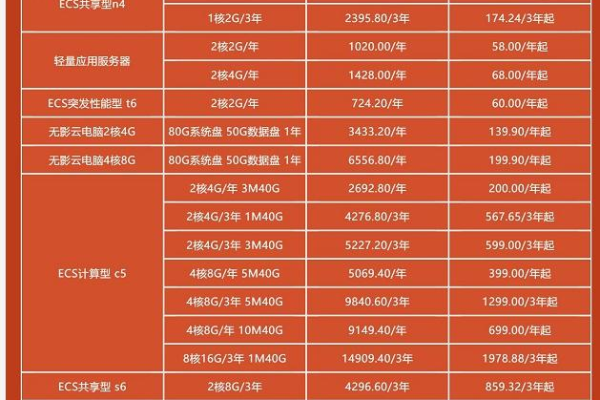
价格对比:根据预算选择合适的供应商,注意比较不同供应商的价格和计费方式。
配置规模:根据业务需求选择适当的配置和规模,确保满足性能需求。
服务支持:选择能提供及时有效技术支持的供应商,确保问题能够得到快速解决。
数据中心位置:考虑数据中心的地理位置,以便获得更好的网络连接和响应速度。
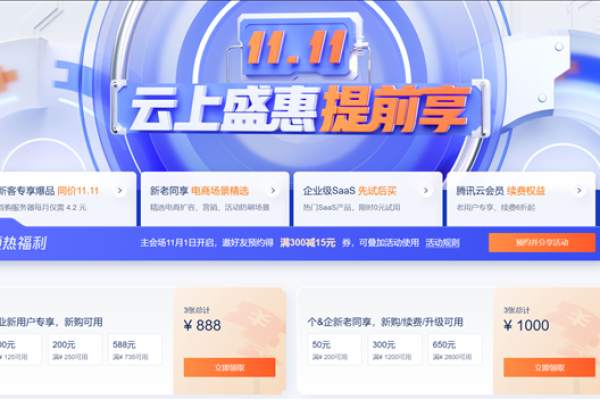
4、促销活动
关注促销信息:双十一期间,多家云服务器供应商会推出折扣和免费试用等优惠活动,通过官方网站和社交媒体获取最新信息。
5、注意事项
安全性:选择有良好安全记录的供应商,确保数据安全和系统防护措施到位。
服务条款:了解清楚服务范围、权益和责任,避免未来可能出现的纠纷。
灵活性扩展性:选择可以提供弹性扩展和升级选项的供应商,以适应未来发展需求。
双十一海外云服务器的选购是一个涉及多方面考量的过程,从了解基本的云服务器知识到明确自身的具体需求,再到精心挑选合适的供应商并关注节日促销活动,每一步都不容忽视。
以上内容就是解答有关“双十一海外云服务器”的详细内容了,我相信这篇文章可以为您解决一些疑惑,有任何问题欢迎留言反馈,谢谢阅读。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20