您知道续费一个TOP域名一年需要多少费用吗?

Top域名续费价格及相关信息
在互联网的世界中,域名是网站的身份标识,选择一个合适的域名对于品牌建设和网络推广至关重要,Top域名作为众多顶级域名之一,因其独特的含义和广泛的应用前景,吸引了许多企业和个人用户的关注,本文将详细介绍Top域名的续费价格、注册与管理、以及与其他域名的比较,帮助您更好地了解和选择Top域名。
Top域名简介
Top域名是2014年新开放的通用顶级域名,具有“顶尖”、“高端”等含义,适用于各种商业、科技、文化等领域的网站,由于其简洁易记的特点,Top域名逐渐成为了众多企业和个人的热门选择。
Top域名续费价格
1. 续费价格范围
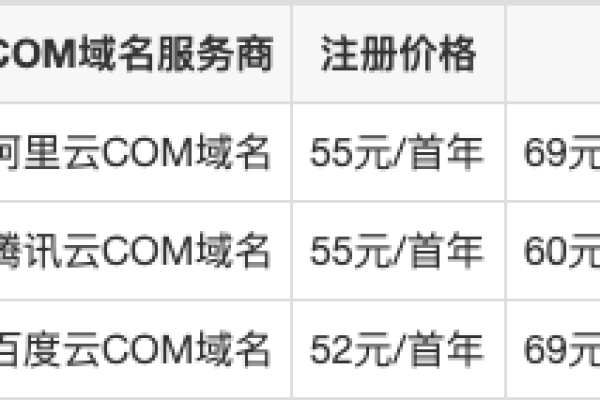
Top域名的续费价格因不同的注册商而有所差异,一般在人民币60元至100元之间,以下是部分知名注册商的Top域名续费价格:
| 注册商 | 续费价格(人民币) |
| 阿里云 | 75元/年 |
| 腾讯云 | 80元/年 |
| 西部数码 | 60元/年 |
| 新网 | 90元/年 |
2. 价格波动因素
Top域名的续费价格可能会受到以下因素的影响:
促销活动:注册商可能会不定期推出优惠活动,降低续费价格。
竞争状况:随着市场竞争的加剧,注册商可能会调整价格策略以吸引用户。
汇率变动:由于域名注册费用通常以美元结算,汇率变动可能间接影响续费价格。
Top域名注册与管理
1. 注册流程
注册Top域名的流程相对简单,一般包括以下几个步骤:
查询域名:在注册商网站上输入想要注册的Top域名,查看是否已被注册。
填写信息:提供个人或企业的真实信息,包括姓名、联系方式、邮箱等。
支付费用:按照注册商的要求支付相应的注册费用。
完成注册:支付成功后,注册商会为您完成域名的注册工作。
2. 管理方法
注册成功后,您可以通过注册商提供的控制面板对Top域名进行管理,包括:
更新DNS记录:设置A记录、CNAME记录等,实现域名解析。
修改WHOIS信息:更新域名所有者的联系信息。
续费与赎回:在域名到期前进行续费操作,避免域名被删除;如果忘记续费,可以在规定时间内进行赎回。
隐私保护:启用WHOIS隐私保护功能,隐藏您的个人信息。
Top域名与其他域名比较
1. 与.com域名的比较
知名度:.com域名是最早的顶级域名之一,具有较高的知名度和认可度;Top域名相对较新,知名度较低。
适用性:.com域名适用于各种类型的网站,尤其是商业网站;Top域名则更适合表达“顶尖”、“高端”等概念的网站。
价格:.com域名的注册和续费价格通常较高;Top域名的价格相对较低。
2. 与.cn域名的比较
地域性:.cn域名是中国的国家顶级域名,主要面向中国市场;Top域名则没有地域限制,适合全球使用。
政策要求:.cn域名的注册和使用受到中国相关法律法规的限制,需要实名认证;Top域名的政策要求相对宽松。
价格:.cn域名的注册和续费价格与Top域名相近,但具体价格仍需根据注册商而定。
相关问题与解答
1. Top域名可以转出到其他注册商吗?
答:是的,Top域名支持转移注册商,在转移过程中,您需要确保原注册商已解锁域名,并获取转移码,在新的注册商处提交转移申请,并按照要求完成验证步骤,转移过程可能需要几天时间来完成。
2. Top域名的续费宽限期是多久?
答:Top域名的续费宽限期一般为30天,在宽限期内,您可以正常续费并保留域名的所有权,如果超过宽限期仍未续费,域名将进入赎回期,在赎回期内,您需要支付额外的费用来恢复域名的使用权,如果连赎回期也未处理,域名最终将被删除并释放给公众重新注册。
到此,以上就是小编对于“top域名续费一年多少钱?top域名续费价格”的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22