个人制作网站需要投入多少资金?

个人制作网站的成本取决于多个因素,包括网站的规模、功能需求、设计复杂度以及是否选择聘请专业人士来完成,以下是一些主要成本构成和大致的价格范围:
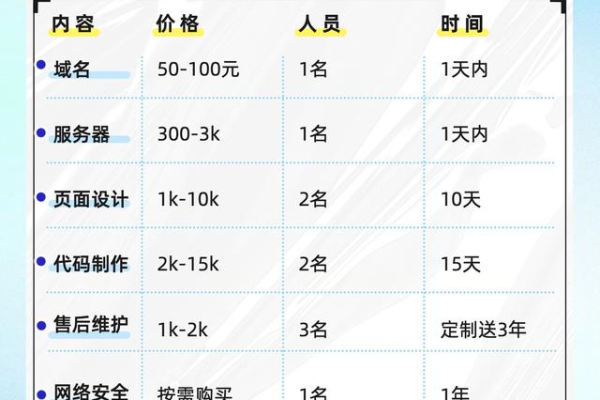
域名注册费用
新域名: 通常在$10-$50/年之间,具体价格根据域名后缀(如.com, .net, .org等)和注册商的不同而有所差异。
已有域名: 如果购买已经注册的域名,价格可能会更高,甚至达到数千或数万美元,这取决于域名的价值和抢手程度。
网站托管服务
共享主机: 最经济的选择,适合小型个人网站或博客,价格通常在$3-$10/月。
VPS主机: 提供更高的性能和控制,适合中等规模的网站,价格大约在$20-$100/月。
独立服务器: 对于大型网站或需要高度定制的环境,价格可以从$50/月起跳,甚至更高。
云服务: 如AWS, Google Cloud, Microsoft Azure等,按使用量付费,初期可能较低,但随着流量增加费用也会上升。

网站设计与开发
模板/CMS: 使用WordPress等免费或低成本的内容管理系统,搭配免费或付费主题($30-$100),可以大大降低开发成本。
自定义设计: 如果你想要独一无二的设计,可能需要聘请网页设计师或开发者,费用从$500到数千美元不等,取决于项目的复杂性。
插件与功能开发: 根据需要添加的功能,如电子商务平台、会员系统、多语言支持等,开发成本会相应增加。
维护与更新
内容更新: 定期发布新内容或产品信息,这部分如果是自己操作则几乎无成本。
技术维护: 包括软件更新、安全检查、备份等,如果自己管理,主要是时间成本;如果外包,可能需要支付一定的月费或年费。

营销与推广
SEO优化: 提高搜索引擎排名,可以是一次性投资($500-$2000)或持续的月度服务($200-$1000+)。
广告投放: 包括Google AdWords、社交媒体广告等,预算完全根据你的营销目标而定,可以从每月几十美元到几千美元不等。
| 项目 | 预估成本(年) |
| 域名注册 | $10-$50 |
| 网站托管 | $36-$1200(取决于服务类型) |
| 设计与开发 | $0(使用模板)$上不封顶(定制开发) |
| 维护与更新 | 免费(自行管理)$2400(外包服务) |
| SEO与营销 | $0(自学)$上不封顶(专业服务) |
一个基本的个人网站可能只需要几百美元的初始投资(使用模板和共享主机),但如果追求更专业的设计和高级功能,成本可以迅速上升至数千甚至数万美元,重要的是明确你的需求和预算,然后据此做出合理的规划。
FAQs
Q1: 我应该如何选择网站托管服务?
A1: 选择网站托管服务时,首先要考虑的是网站的需求和预期流量,对于刚开始的个人项目或小企业,共享主机是一个成本效益高的选择,因为它提供了必要的功能同时保持低成本,随着网站的成长和访问量的增加,你可能需要考虑升级到VPS或专用服务器以获得更好的性能和控制,也要考虑客户支持的质量、服务器的可靠性以及是否提供额外的服务,如SSL证书安装、自动备份等,比较不同提供商的价格和服务条款,确保它们符合你的预算和长期需求。

Q2: 为什么域名注册费用会有这么大的差异?
A2: 域名注册费用的差异主要由以下几个因素造成:不同的顶级域名(TLD)如.com、.net、.org等,其注册成本本身就不同,域名的长度和易记性也会影响价格,简短、易于记忆的域名往往更贵,某些域名可能因为之前被用于建立过知名网站而具有较高的市场价值,域名注册商之间的竞争也会导致价格差异,一些注册商可能会提供折扣或促销活动来吸引用户,续费价格通常高于首年注册价格,这也是需要考虑的一个因素,在选择域名时,除了考虑初始注册费用外,还应该关注续费价格以及是否有任何隐藏费用。
到此,以上就是小编对于“个人制作网站多少钱”的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22