如何编写计算器的易语言源代码?

易语言计算器源码示例:,“
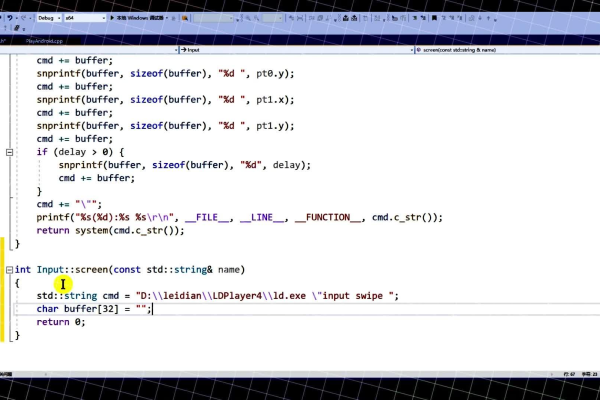
e,主程序, 变量 数字1, 数字2, 运算符, 结果, 输入 "请输入第一个数字:", 数字1, 输入 "请输入运算符(+, , *, /):", 运算符, 输入 "请输入第二个数字:", 数字2, 运算符 = "+" 结果 = 数字1 + 数字2, 否则如果 运算符 = "" 结果 = 数字1 数字2, 否则如果 运算符 = "*" 结果 = 数字1 * 数字2, 否则如果 运算符 = "/" 结果 = 数字1 / 数字2, 输出 "结果是:", 结果,“
易语言是一种中文编程语言,以下是一个简单的计算器易语言源码:
“`易语言
程序源代码
.版本 2
子程序 按钮_点击(整数型, 文本型)
变量 数字1, 数字2, 结果: 双精度浮点数
变量 操作符: 文本型
(参数1 = 1) 则
数字1 = 取双精度浮点数(文本框1.内容)
操作符 = 下拉框1.内容
文本框1.内容 = ""
否则
数字2 = 取双精度浮点数(文本框1.内容)
根据 操作符 做
"+" 到 "加法": 结果 = 数字1 + 数字2
"" 到 "减法": 结果 = 数字1 数字2
"*" 到 "乘法": 结果 = 数字1 * 数字2
"/" 到 "除法": (数字2 <> 0) 则 结果 = 数字1 / 数字2 否则 提示("除数不能为0")
其他: 提示("无效的操作符")
结束根据
文本框1.内容 = 转文本(结果)
结束如果
子程序结束
这个源码定义了一个名为按钮_点击的子程序,它接收两个参数:一个整数型参数(用于区分是哪个按钮被点击)和一个文本型参数(用于存储输入的数字和操作符),在这个子程序中,我们首先声明了三个变量:数字1、数字2和结果,以及一个操作符变量,我们根据参数1的值来判断是第一个数字还是第二个数字被输入,如果是第一个数字,我们将其转换为双精度浮点数并存储在数字1中,同时将操作符存储在操作符变量中,如果是第二个数字,我们将其转换为双精度浮点数并存储在数字2中,然后根据操作符执行相应的计算并将结果存储在结果变量中,我们将结果显示在文本框1中。
以上内容就是解答有关“计算器易语言源码”的详细内容了,我相信这篇文章可以为您解决一些疑惑,有任何问题欢迎留言反馈,谢谢阅读。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/146392.html