存储过程 定义变量

DECLARE语句来定义变量。
存储过程与定义变量的深度解析
在数据库管理领域,存储过程和变量定义是两个极为关键的概念,它们对于优化数据库操作、提高数据处理效率以及增强代码的可维护性都有着不可忽视的作用。
一、存储过程
(一)定义
存储过程(Stored Procedure)是一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,它可以接受输入参数、执行一系列复杂的数据库操作,并能够返回结果集或输出参数,在一个电商数据库中,可能存在一个用于处理订单提交的存储过程,它会涉及到库存检查、订单记录插入、用户积分更新等多个数据库表的操作,当有新订单提交时,只需调用这个存储过程,就能按照预设的逻辑有序地完成所有相关操作,而无需每次编写大量重复且容易出错的 SQL 语句。
(二)优点
1、提高性能:存储过程在首次执行时会被编译,后续调用可直接执行编译后的代码,减少了 SQL 语句重复编译的时间开销,尤其是对于复杂查询和大量数据处理的情况,性能提升显著,一个涉及多表连接和复杂条件过滤的报表生成存储过程,在首次编译后,每次运行时能快速响应,大大缩短了用户等待时间。
2、增强代码复用性:将常用的数据库操作逻辑封装在存储过程中,可以在多个应用程序或不同场景下重复调用,以企业资源规划(ERP)系统为例,计算员工绩效奖金的存储过程可以在月度考核、季度归纳等不同模块中被调用,避免了相同代码的多次编写,降低了开发和维护成本。
3、提高数据安全性:通过存储过程可以对用户访问数据库的权限进行精细控制,开发人员可以授予用户执行特定存储过程的权限,而不必给予他们直接操作底层数据表的高权限,从而有效防止了数据误操作和反面改动,普通业务人员只能通过调用特定的数据查询存储过程来获取部分业务数据,而不能直接对数据库进行增删改操作。
二、定义变量
(一)在存储过程中的定义
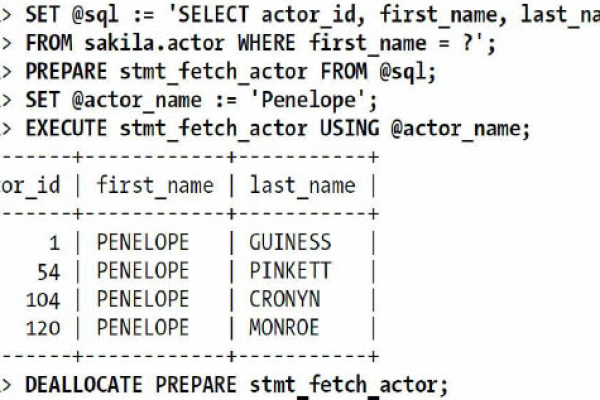
在存储过程内部,可以使用变量来临时存储数据值,以便在后续的 SQL 语句中使用,不同的数据库管理系统(DBMS)有不同的变量定义语法,以常见的 MySQL 和 SQL Server 为例:
| DBMS | 变量定义语法 | 示例 |
| MySQL | DECLARE 变量名 数据类型; |
DECLARE total_price DECIMAL(10,2); |
| SQL Server | DECLARE @变量名 数据类型; |
DECLARE @product_count INT; |
这些变量可以在存储过程中用于存储中间计算结果、传递参数值等,在一个计算订单总价的存储过程中,可以先定义一个变量来存储每个商品的单价与数量的乘积,然后累加到总价变量中,最终返回订单总价。
(二)变量的作用域
存储过程中定义的变量作用域通常局限于该存储过程内部,这意味着在一个存储过程 A 中定义的变量不能直接在存储过程 B 中使用,除非通过参数传递或全局变量(部分 DBMS 支持)的方式进行交互,这种作用域限制有助于避免变量命名冲突和数据的意外干扰,使存储过程的逻辑更加清晰和独立。
FAQs
问题 1:存储过程可以嵌套调用吗?
答:是的,存储过程可以嵌套调用,即一个存储过程可以调用另一个存储过程,在一个大型的企业级应用中,可能有多个层次的业务逻辑,主存储过程负责整体业务流程的控制,当需要执行某个特定的子任务时,它可以调用相应的子存储过程,在处理客户订单的主存储过程中,如果需要验证客户信用信息,就可以调用一个专门用于信用验证的子存储过程,嵌套调用可以使代码结构更加清晰,便于维护和管理,同时也提高了代码的复用性,不过,在嵌套调用时需要注意递归调用可能导致的性能问题和堆栈溢出风险,要合理设计调用层次和退出条件。
问题 2:如何在存储过程中使用变量来处理异常情况?
答:在存储过程中处理异常情况时,可以利用变量来记录错误信息或状态,大多数数据库管理系统都提供了错误处理机制,如 TRY…CATCH(SQL Server)或 DECLARE…HANDLER(MySQL),在 TRY 块中执行正常的业务逻辑,如果发生错误,程序会跳转到 CATCH 块,在 CATCH 块中,可以定义一个变量来存储错误编号或错误消息,然后根据这个变量的值来决定进一步的处理方式,在 SQL Server 中:
BEGIN TRY
-正常业务逻辑代码
IF @some_condition = 0
BEGIN
RAISERROR('An error occurred', 16, 1);
END
END TRY
BEGIN CATCH
DECLARE @ErrorMessage NVARCHAR(4000);
DECLARE @ErrorSeverity INT;
DECLARE @ErrorState INT;
SELECT @ErrorMessage = ERROR_MESSAGE(), @ErrorSeverity = ERROR_SEVERITY(), @ErrorState = ERROR_STATE();
-根据错误信息进行处理,如记录日志、回滚事务等
PRINT 'Error: ' + @ErrorMessage;
END CATCH;
通过这种方式,可以在存储过程中灵活地应对各种异常情况,保证程序的健壮性和稳定性。
小编有话说:存储过程和变量定义是数据库编程中的两大基石,深入理解和熟练运用它们,能够让数据库开发更加高效、灵活且易于维护,无论是开发小型项目还是大型企业级应用,掌握好这些技术都能为数据处理和业务逻辑实现提供强大的支持,助力开发者构建出稳定可靠的数据库系统。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/145892.html