
上一篇
如何在MySQL中根据特定列去除重复数据并优化设计以减少冗余?
在mysql数据库中,去重操作可以通过使用distinct关键字或group by子句实现,以消除查询结果中的重复行。设计时避免冗余数据可减少存储空间和提高查询效率,同时确保数据的一致性和完整性。
在MySQL数据库管理与操作中,去除重复数据是维护数据质量的一项重要工作,本文将详细介绍在MySQL中如何按某列去除重复的数据,并提供相应的操作指导,具体如下:
1、使用DISTINCT关键字
基本用法:SELECT DISTINCT column1, column2, ... FROM table_name; 此语句将返回在指定的列上没有重复的行,如果应用到多个列上,那么这些列的组合必须是唯一的。
应用场景:当需要从单列或多列中筛选出唯一值,且不需要其他列的数据时,DISTINCT是最直接的选择,若要找出表中不同的org_id,可以使用SELECT DISTINCT org_id FROM table_name;。
2、使用GROUP BY子句
基本用法:SELECT column1, column2, ... FROM table_name GROUP BY column1, column2, ...; 此语句不仅去重,还可以结合聚合函数如SUM、COUNT等,对分组后的数据进行运算处理。
应用场景:当需要对去重后的某一列或多列数据进行聚合运算时,GROUP BY显示出其强大的功能,要计算每个stu_id的总分数,可以使用SELECT stu_id, SUM(score) FROM table_name GROUP BY stu_id;。
3、配合GROUP_CONCAT使用
基本用法:在GROUP BY查询中,可以使用GROUP_CONCAT函数来合并同一组内的其他字段值,这样就能既实现去重,又不完全丢失信息。
应用场景:当去重的同时,还需要保留除分组列外其他列的部分信息时,我们只想查看每个学科的最新一篇论坛帖子,可以使用此方法。
4、窗口函数
基本用法:使用窗口函数如ROW_NUMBER() PARTITION BY column1 ORDER BY column2,能够为每一组分区内的行分配一个唯一的数字标识,从而筛选出每组的唯一行。
应用场景:适用于更复杂的去重需求,如需要基于某列去重,同时按照另一列的值进行排序,从而保留每组中某个特定条件下的行。
5、删除重复数据
基本用法:若要从表中彻底移除重复行,可以配合DELETE语句和JOIN查询来实现,通过INNER JOIN或LEFT JOIN将表自身连接到一个子查询,该子查询找到所有重复的行,然后在DELETE语句中删除这些行。
应用场景:当不仅要查询去重后的结果,而且要从物理上删除重复数据时,这一方法是必须的,清除所有email相同但username不同的重复用户记录。
在了解以上内容后,以下还有一些其他建议:
在使用GROUP BY去重时,确保所有选择的列都在GROUP BY子句中,否则可能会由于非确定性行为造成错误结果。
使用窗口函数去重可以非常灵活地控制哪些行被保留,但性能上可能不如DISTINCT和GROUP BY。
删除物理数据前务必备份数据,防止不可逆的损失。
在MySQL中去除重复数据可以通过多种方式实现,包括使用DISTINCT、GROUP BY、窗口函数以及配合表连接的DELETE操作等,每种方法都有其适用的场景和特点,合理选择适合的方法,可以有效地满足不同的数据处理需求,接下来将通过一些常见问题进一步巩固这些概念。
FAQs
Q1: 为什么在使用GROUP BY进行查询时,有些列不能被选中?
A1: 在使用GROUP BY进行查询时,SELECT语句中的列要么是分组列,要么被包含在聚合函数中,这是因为在分组后的每个组内,非分组列可能包含多个值,若不使用聚合函数,数据库无法确定返回哪个值,这将导致潜在的非确定性查询结果。
Q2: 如何确定何时使用DISTINCT而非GROUP BY?
A2: 当你只需要从结果集中移除重复的行,而不需要执行任何聚合运算时,使用DISTINCT是更简单直接的选择,相反,如果你需要在去重的同时对数据进行聚合运算,如求和、计数等,GROUP BY则是更好的选择,因为它可以同时完成分组和聚合运算。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/145690.html
相关文章
-
如何在MySQL中去除重复数据以优化设计并减少冗余?
-
如何在MySQL中有效去除重复数据以优化设计并减少冗余?
-
如何有效去除MySQL数据库中的重复数据以优化设计并减少冗余?
-
如何在MySQL中查询并去除表中的重复字段以优化设计冗余?
-
如何在MySQL数据库中有效去除重复数据以避免冗余设计?
-

如何在MySQL数据库中去除重复数据并仅保留一条记录?
-
如何在MySQL查询中有效去除重复数据以优化数据库设计?
-
如何有效使用MySQL查询去除数据重复并避免设计冗余?
-
如何在MySQL中根据特定条件高效筛选数据?
-
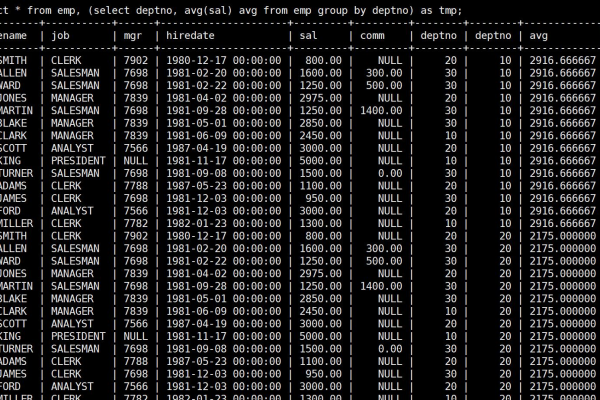
如何在MySQL中合并两个表并去除重复数据?
-

如何在MySQL中设计数据表以避免重复和冗余?
-
如何在MySQL数据库中有效去除重复数据?
-
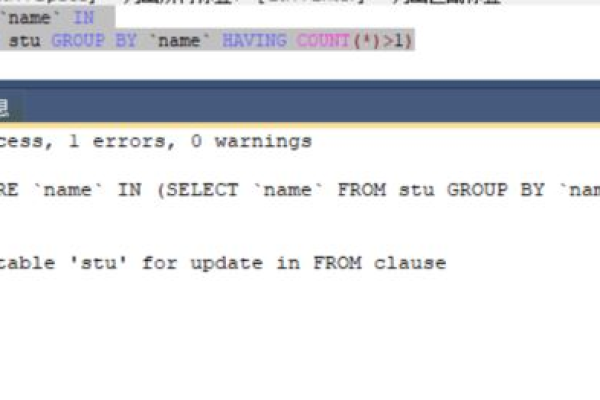
如何利用MySQL高效删除重复记录以消除重复来电问题?
-
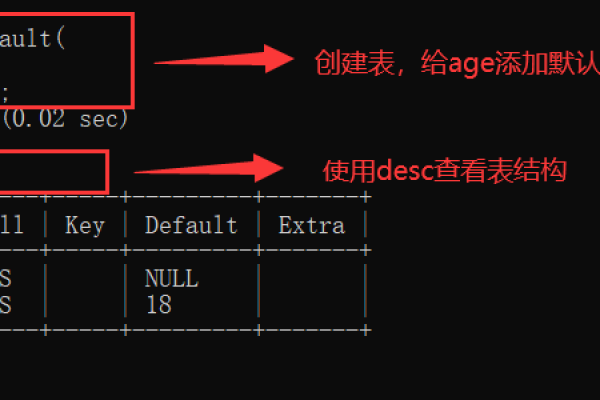
如何利用MySQL根据时间去重复数据库以避免设计冗余的用例?
-

如何在MapReduce框架中实现排序的同时有效去除重复数据?
-
如何编写SQL语句来去除重复数据?
-
如何在MySQL中选择前五行数据并依据特定字段进行筛选?
-
如何实现在dedecms5.7中根据特定关键词或ID调用相关文档?
-
如何有效配置PCS7冗余服务器以实现数据去冗余?
-
如何在MySQL中有效去除重复的来电记录?
-
如何在MySQL数据库中有效地去除重复记录并保留唯一条目?