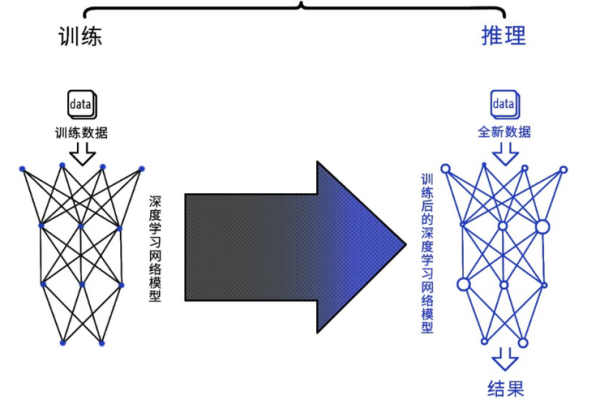
dbm 神经网络

深度玻尔兹曼机(Deep Boltzmann Machine,简称DBM)是一种深度学习模型,它属于生成模型的范畴,以下是关于DBM神经网络的详细解释:
1、核心概念
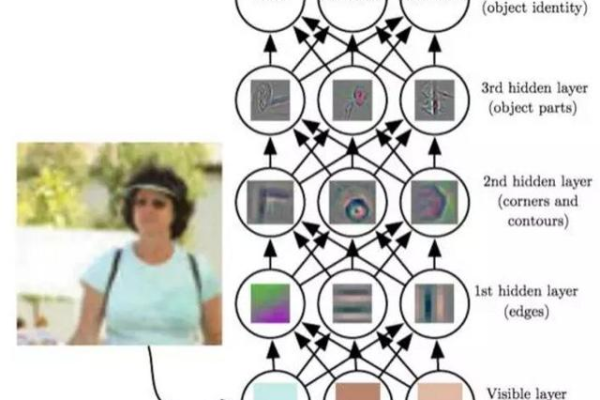
可见节点与隐藏节点:DBM由两种类型的节点组成,即可见节点(visible units)和隐藏节点(hidden units),可见节点用于表示输入数据,而隐藏节点则用于学习数据的特征表示。
能量函数:DBM定义了一个能量函数(energy function),该函数衡量了可见节点和隐藏节点之间的兼容性或相似性,能量函数的值越低,表示节点之间的匹配程度越高。
概率分布:DBM通过能量函数定义了可见节点和隐藏节点的概率分布,这个概率分布可以用来生成新的数据样本,或者计算给定数据的似然度。
2、工作原理
正向传播:在正向传播阶段,DBM根据输入数据计算每个隐藏节点的激活概率,这个过程通常使用sigmoid函数或其他非线性激活函数来实现。
采样:一旦计算出隐藏节点的激活概率,DBM会通过采样来生成隐藏层的活动状态,这种采样可以是确定性的(如使用sigmoid函数的输出作为二进制值),也可以是随机的(如使用伯努利分布进行采样)。
反向传播:在反向传播阶段,DBM根据输出层和隐藏层之间的误差来更新模型的权重,这个过程通常使用梯度下降或其他优化算法来实现。
3、训练方法
对比散度(Contrastive Divergence, CD):CD是一种用于训练DBM的常用算法,它通过最大化对数似然函数来更新模型参数,使得模型能够更好地拟合训练数据。
逐层贪婪预训练:由于DBM的复杂性,直接训练整个网络可能会很困难,一种常见的策略是采用逐层贪婪预训练的方法,这种方法首先训练一个单层的RBM(Restricted Boltzmann Machine),然后将其堆叠起来形成DBM,并继续训练下一层。
4、应用
无监督学习:DBM可以用于无监督学习任务,如特征提取、聚类和降维等。
有监督学习:通过添加标签信息,DBM也可以用于有监督学习任务,如分类和回归等。
5、优缺点
优点:DBM具有强大的表达能力,可以学习复杂的数据分布;它可以通过学习数据的内在结构来进行特征提取和表示学习;它还具有一定的鲁棒性,能够处理噪声和缺失数据。
缺点:DBM的训练过程可能比较复杂且耗时;它需要大量的标记数据来进行有效的训练;DBM的性能也可能受到模型复杂度和超参数选择的影响。
深度玻尔兹曼机是一种强大的深度学习模型,它在许多领域都有广泛的应用前景,由于其复杂性和训练难度,实际应用中需要仔细设计模型结构和训练策略以获得最佳性能。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22