
上一篇
如何优化MongoDB MapReduce的性能?
MongoDB的MapReduce操作在处理大数据量时可能会遇到性能瓶颈。为了优化其性能,可以采取以下措施:适当地调整map和reduce函数以减少计算复杂度,合理设置并行度以利用多核处理器,以及使用合适的数据模型和索引来加速查询。监控资源使用情况并适时调整硬件配置也是提升性能的关键步骤。
在探讨MongoDB中的MapReduce性能调优方面,需要了解MapReduce在MongoDB中的作用以及为何需要对其进行性能调优,MapReduce是MongoDB提供的一种数据处理模式,它能灵活处理大规模数据集,尽管MongoDB的MapReduce由于多种优化和更新,其性能已有所提升,但与聚合框架相比,仍存在一定的性能差距,以下是针对MongoDB MapReduce性能调优的详细措施:

1、索引优化
索引策略调整:根据数据查询的模式,合理设计索引可以显著提升MapReduce作业的运行效率,通过为MongoDB集合中的文档创建适当的索引,可以减少MapReduce执行过程中的文档扫描范围,从而缩短执行时间。
监控索引性能:使用explain或者profiler等工具,分析并监控索引的使用情况和性能表现,及时调整索引策略,去除不必要的索引,增加对提升性能有帮助的索引。
2、硬件配置调整
优化内存配置:调整WiredTiger存储引擎的缓存大小(wiredTigerCacheSizeGB),以便更高效地处理数据读写操作,提高MapReduce作业的数据读取速度。
网络和存储优化:确保网络带宽和存储I/O性能充足,特别是在分布式环境中,网络延迟和磁盘I/O可能会成为限制MapReduce性能的瓶颈。
3、代码级优化
优化Map和Reduce函数:精简Map和Reduce函数中的业务逻辑,尽量避免复杂的运算和数据操作,以减少不必要的性能开销。
使用合并器(Combiner):在Map阶段使用合并器,可以在数据传输到Reduce之前先进行部分数据的合并,减少网络传输量和Reduce阶段的计算压力。
4、并行处理
分片并行处理:利用MongoDB的分片功能,将数据分布在多个分片上并行执行MapReduce作业,通过并行处理加快数据分析的速度。
5、监控与评估
使用监控工具:运用mongostat和mongotop等工具实时监控数据库的操作状态,找出性能瓶颈,并针对性地进行优化。
评估工作负载:通过profiler工具捕捉慢查询语句,评估当前的工作负载,分析哪些操作影响了系统性能,据此进行优化。
6、部署架构优化
合理设计部署架构:根据数据量和访问模式,设计合理的MongoDB部署架构,如副本集、分片集群等,确保系统的高可用和负载均衡。
7、定期维护
数据清理和维护:定期对MongoDB进行数据清理和维护,比如删除旧的文档、清理碎片等,保持数据整洁,有助于MapReduce作业的顺畅运行。
8、尝试其他替代方案
考虑聚合框架:尽管MapReduce非常灵活,但聚合框架通常能提供更好的性能,如果可能,考虑使用聚合框架来完成数据分析任务。
在了解以上内容后,以下还有一些其他建议:
物尽其用的原则:在创建索引时,应权衡索引带来的查询性能提升与其对写操作造成的性能损耗之间的关系。
合适的数据模型:选择适合MapReduce处理的数据模型,能够简化数据处理过程,避免在MapReduce中进行复杂的数据转换。
在文章末尾,按照要求提供一个相关问答FAQs环节,解答有关MongoDB MapReduce性能调优的常见问题。
FAQs
Q1: 如何判断我的MongoDB MapReduce作业是否需要性能调优?
A1: 如果您发现MapReduce作业运行时间过长,占用大量系统资源,或者监控工具显示数据库响应缓慢,这些都可能是需要进行性能调优的信号,您可以使用profiler工具确定慢查询,并通过mongostat和mongotop观察数据库的实时性能指标。
Q2: 是否所有的MapReduce作业都能从性能调优中受益?
A2: 并非所有MapReduce作业都能显著受益于性能调优,对于一些简单且数据量不大的作业,性能提升可能不明显,但对于处理大量数据或逻辑复杂的作业,性能调优往往能带来显著的性能提升。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/145479.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
Morphia MapReduce: 如何有效使用MongoDB的MapReduce功能?
-
如何实现Mongo MapReduce对接?探索Mongo MapReduce例子
-
如何将MongoDB MapReduce的输出结果与MongoDB数据库对接?
-
如何优化MongoDB中MapReduce的性能?
-
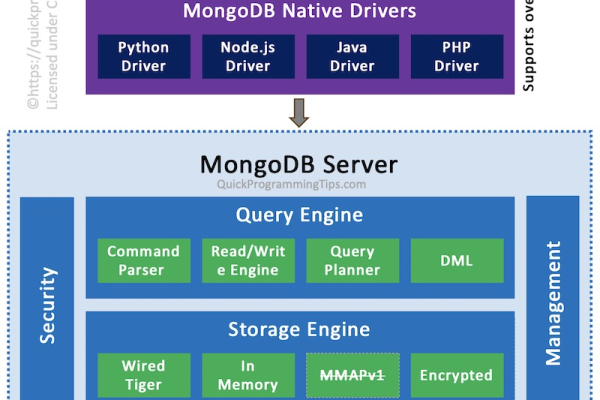
mongodb价格(mongodb go)(mongodb多少钱)
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
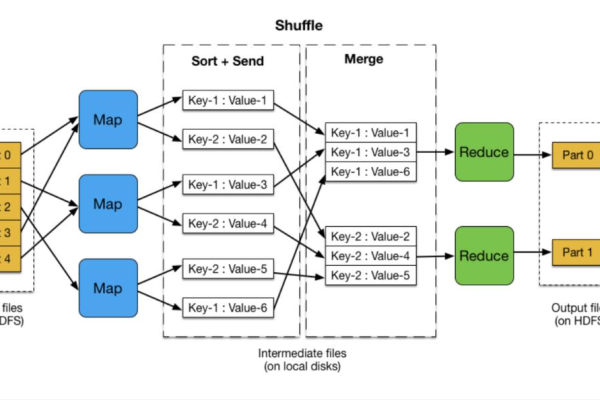
如何优化MapReduce节点以提高MRS MapReduce作业的性能?








