
上一篇
如何在MapReduce中处理多路径输入并保持CSV文件的读取顺序?
MapReduce 支持多路径输入,允许用户指定多个文件或目录作为数据源。在读取CSV文件时,MapReduce会按照给定的路径列表顺序依次处理每个文件。如果需要特定的读取顺序,可以在代码中调整输入路径的顺序来实现。
在大数据处理领域,MapReduce框架是Hadoop生态系统中的一项核心技术,它使得处理海量数据集成为可能,在实际应用中,经常会遇到需要从多个文件中读取数据的场景,本文将深入探讨如何在MapReduce中使用多路径输入来读取CSV文件,并保持数据的处理顺序,具体分析如下:

1、使用FileInputFormat添加多路径输入
方法调用:通过FileInputFormat.addInputPath()方法,可以向MapReduce作业添加多个输入路径。
路径格式:多个路径是用逗号分隔的字符串,形如:"path1,path2,path3",这样设置后,MapReduce会按照设定的路径顺序依次读取数据。
2、利用MultipleInputs处理多个输入
不同逻辑处理:当需要对不同输入文件应用不同的处理逻辑时,可以使用MultipleInputs类,它允许为每个输入文件指定不同的Mapper类。
代码实现:在代码中导入必要的包,然后使用MultipleInputs.addInputPath()方法添加特定的Mapper类和对应的路径。
3、全局数据和配置管理
保存全局数据:在MapReduce中,可以通过读写HDFS文件、配置Job属性或使用DistributedCache来保存全局数据,以便在任务中共享。
配置排序:MapReduce本身具有排序过程,默认的key值排序,这对于处理多路径输入时保证数据顺序尤为重要。
4、获取每条数据的文件名
Map代码内获取:在编写Map函数时,可以通过特定代码获得每条数据所属的原始文件名,这有助于跟踪数据处理的过程。
5、优化多路径输入的性能
合理设置路径:选择适当的输入路径可以减少读取时间,将物理位置接近的数据放在同一路径下,以减少磁盘I/O操作。
调整缓冲区大小:通过调整MapReduce框架的缓冲区大小(如mapreduce.map.buffer),可以提高数据处理效率。
可以看出在MapReduce中使用多路径输入读文件顺序涉及到的关键点包括正确使用FileInputFormat和MultipleInputs类添加路径、管理全局数据与配置、获取数据文件名以及性能优化等,这些步骤确保了在处理大规模数据集时能够高效且有序地进行数据分析和处理。
FAQs
Q1: 如何处理多个输入文件中的不同数据格式?
A1: 当遇到多种数据格式时,可以使用MultipleInputs类为每种格式的数据指定一个特定的Mapper类,这意味着你可以在处理逻辑中根据不同格式定制化解析和转换数据的方法,从而实现对不同数据格式的兼容处理。
Q2: MapReduce程序中如何优化多路径输入的读取速度?
A2: 优化多路径输入的读取速度可以从以下几个方面考虑:合理地组织和分布数据,尽量让物理位置近的数据在同一路径下;适当增加MapReduce框架的缓冲区大小,减少频繁的磁盘I/O操作;确保所有的输入路径都有良好的磁盘读写速度,避免个别路径成为瓶颈,通过这些方法,可以显著提升数据处理的速度和效率。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/145476.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
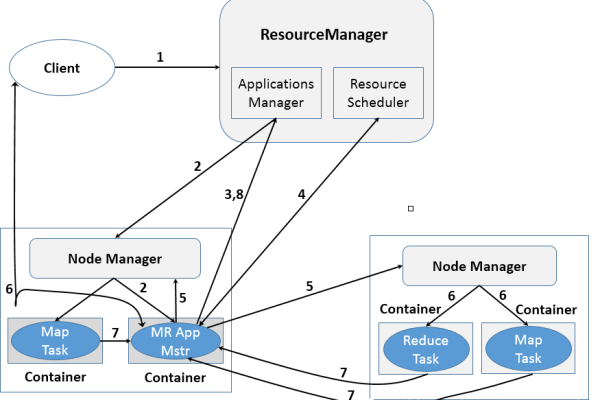
如何在MapReduce中实现多路径输出并安装必要的多路径软件?
-
如何在MapReduce中处理多个CSV文件输入?
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
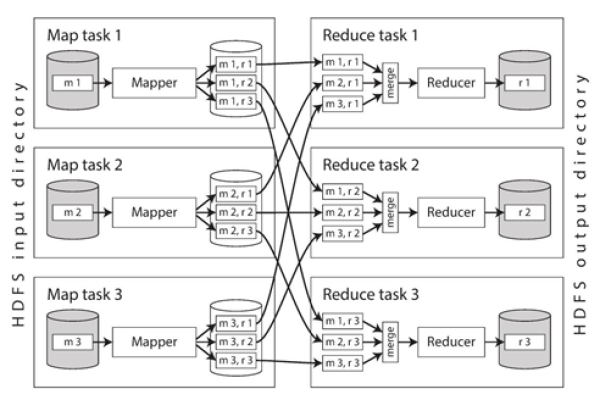
如何实现MapReduce处理多个CSV文件的输入?
-
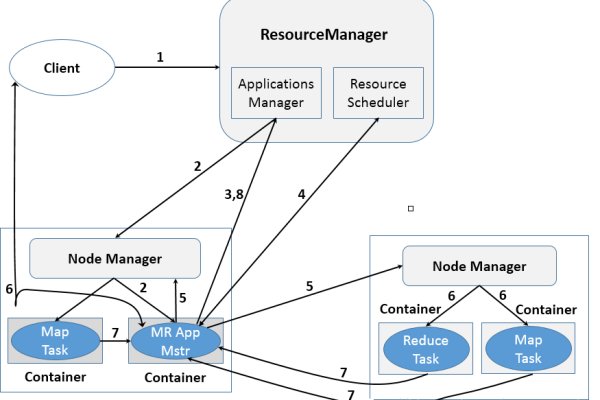
如何安装并配置MapReduce以支持多路径输入?
-
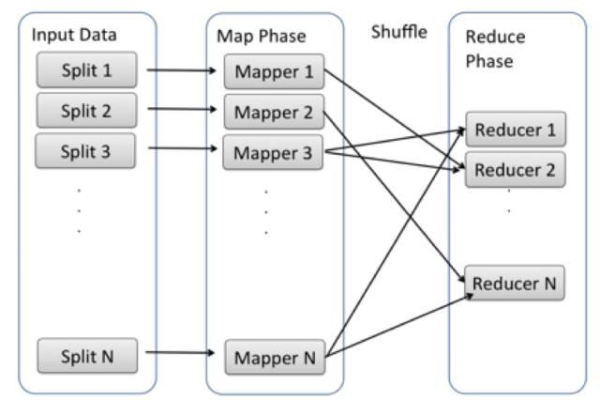
如何实现MapReduce中的多路径输出并安装相应的软件?
-
如何解决在Linux上使用MapReduce时输入Windows路径导致安装路径输入不合法的问题?








