
上一篇
如何有效使用MapReduce来合并文件夹中的多个文件?
MapReduce是一种编程模型,用于处理和生成大数据集。在合并文件夹的过程中,MapReduce将数据分成多个段,每个段由一个单独的任务处理。这些任务并行执行,最后将结果合并以得到最终的输出。这种方法可以有效地处理大规模数据,提高计算效率。
在MapReduce框架中,合并文件夹和合并段是两个关键步骤,旨在提高数据处理的效率和性能,这一过程涉及将分散的数据文件整合在一起,以便于进行更有效的数据操作和分析,本文将详细探讨如何在MapReduce环境中实现文件夹的合并与优化数据处理。
MapReduce模型的核心思想是将大规模数据处理任务分发到多个计算节点上并行处理,在此模型中,"Map"阶段负责将任务分解成更小的子任务,而"Reduce"阶段则聚焦于处理和整合这些子任务的结果,在数据处理过程中,合并文件夹和合并段的操作至关重要,它们直接影响到数据处理的速度和效率。
Map端合并(Combiner)
Map阶段的输出通常需要被传输到Reduce节点进行处理,但在此之前,可以利用Combiner来减少网络传输的数据量,Combiner本质上是一个在Map端运行的小型Reducer,它的作用是在数据离开Map节点之前,对生成的键值对进行局部汇总,这样做可以显著减少数据量,从而减轻网络传输的负担。
使用场景
当一个Map任务生成的中间输出中包含大量具有相同键的值时,Combiner尤其有用,在计数任务中,Combiner可以预先对相同键的值进行求和,从而减少数据传输量。
Reduce端合并
在MapReduce的Reduce阶段,来自各个Map节点的数据将被整合和进一步处理,Reducer的任务是对具有相同键的值进行归约操作,如统计、累加等,在这个过程中,不同来源的数据需要被正确合并以确保数据完整性和准确性。
方法
1、直接合并:最简单的方式是直接在Reducer中将所有传递过来的数据进行合并,但这可能不是最高效的方法。
2、提前排序:为了优化性能,可以在数据到达Reducer之前进行预排序,这样可以减少后续处理的复杂性。
性能优化策略
环形缓存区
在MapReduce中,环形缓存区(circular buffer)是一种用于存储Map输出数据的内存结构,当此缓存区填满时,可以触发combiner函数进行局部合并,进而减少写入磁盘的数据量。
调整Combiner策略
合理使用Combiner可以显著提升性能,但也需注意其使用条件,Combiner适用于那些满足结合律的操作(如加法),而不适宜于那些不符合的操作(如排序)。
通过上述探讨,我们了解到在MapReduce框架下,合理利用合并文件夹和合并段不仅可以提高数据处理的效率,还可以优化资源的使用,选择合适的合并策略,如适当地使用Combiner和采取适当的数据排序与缓冲措施,对于提升整体性能有着直接的影响。
让我们通过一些常见问题来进一步巩固理解:
FAQs
Q1: Combiner是否可以应用于所有类型的MapReduce作业?
A1: 并非所有的MapReduce作业都适合使用Combiner,Combiner主要适用于那些满足结合律的操作,比如累加、最大最小值查找等,对于那些需要保持数据顺序或精确控制数据的操作,使用Combiner可能会得到错误的结果。
Q2: 在实际应用中如何确定何时使用Combiner?
A2: 判断是否使用Combiner的一个简单方法是观察Map输出的数据量,如果Map输出的数据量很大,并且存在大量的重复键,那么使用Combiner可以有效减少数据传输量和后续处理的压力,如果网络带宽是瓶颈,使用Combiner也可以带来明显的性能提升。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/145185.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
在多个MapReduce串联和多个NameService环境下,MapReduce任务失败的原因是什么?
-
Morphia MapReduce: 如何有效使用MongoDB的MapReduce功能?
-
如何利用MapReduce框架高效读取文件夹中的模型数据?
-
如何理解和使用MapReduce中的cmdenv_MapReduce命令?
-
如何利用MapReduce在本地文件夹中实现单边读和写操作?
-
MapReduce 无法输出至文件?探讨MapReduce与OBS文件系统对接挑战
-
如何有效应用MapReduce中的map和reduce操作?
-
MapReduce技术中的Redie阶段如何影响整个MapReduce工作流程的效率?
-
如何有效解决MapReduce任务中的pending_MapReduce问题?
-
如何通过MapReduce REST API接口管理MapReduce作业?
-
如何使用Java MapReduce API来掌握MapReduce编程?
-
如何利用MapReduce框架实现数据统计?探索MapReduce统计样例代码!
-
MapReduce处理数据时,如何有效执行MapReduce Action?
-
MapReduce 的双轮驱动,如何有效利用两个 MapReduce 任务进行数据处理?
-
MapReduce 无法输出文件,那么在MapReduce对接OBS文件系统时,是否有特定的解决方案来确保数据的持久化存储?
-

如何使用MapReduce来获取指定技能队列中的排队总人数?
-
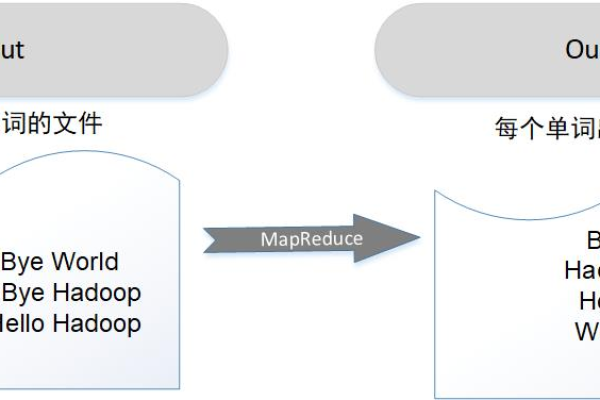
如何高效地使用MapReduce合并多个小文件?
-
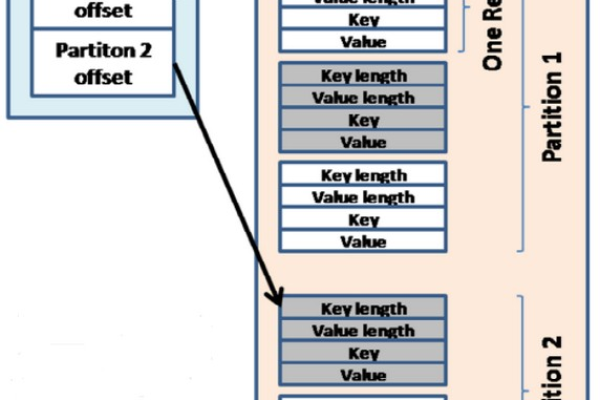
MapReduce Shuffle调优,如何优化MapReduce中的Shuffle过程?
-
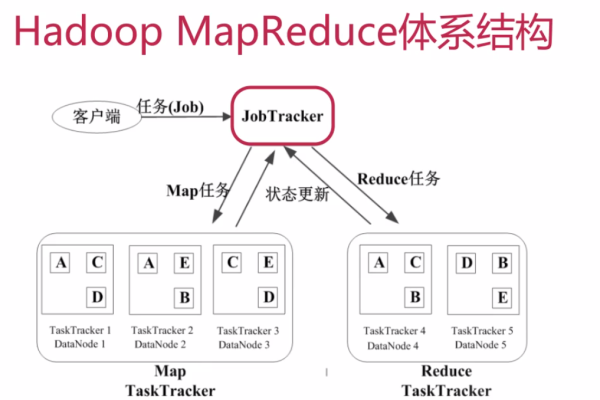
MapReduce JobTracker如何与MapReduce框架中的其他关键组件实现协同与交互?