CDN视频调度如何优化用户体验与网络性能?

CDN(内容分发网络)视频调度是优化视频传输和提升用户体验的重要技术手段,通过智能算法,将用户请求分配到最佳的CDN节点,从而降低延迟、提高带宽利用率并增强系统稳定性,以下是关于CDN视频调度的详细回答:
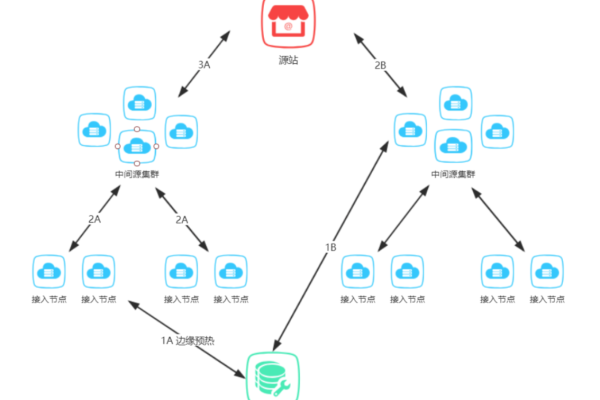
1、智能DNS解析
地理位置分析:根据用户的地理位置,选择最近的CDN节点。
网络运营商识别:识别用户所使用的网络运营商,确保分配到相应运营商的最优节点。
节点负载监控:实时监控各CDN节点的负载情况,避免过载节点被选中。
2、负载均衡
轮询策略:依次将用户请求分配到不同的服务器上,适用于负载均匀的场景。
最小连接数策略:将请求分配到当前连接数最少的服务器,适用于长连接场景。
响应时间策略:根据服务器的响应时间,将请求分配到响应时间最短的服务器,适用于对响应速度要求高的场景。
3、内容缓存
缓存:对不经常变化的内容进行长期缓存,减少源服务器压力。
缓存:通过设置缓存策略,如时间戳验证和ETag,决定是否需要重新获取内容。
边缘缓存缓存到离用户最近的边缘节点,进一步减少传输延迟。
4、边缘计算
数据处理:在靠近用户的边缘节点进行数据处理任务,如数据过滤和预处理,减少中心服务器压力。
智能缓存:利用边缘计算能力,动态调整缓存策略,提高缓存命中率。
实时应用:对于需要实时响应的应用,如在线游戏和实时直播,通过边缘计算减少延迟。
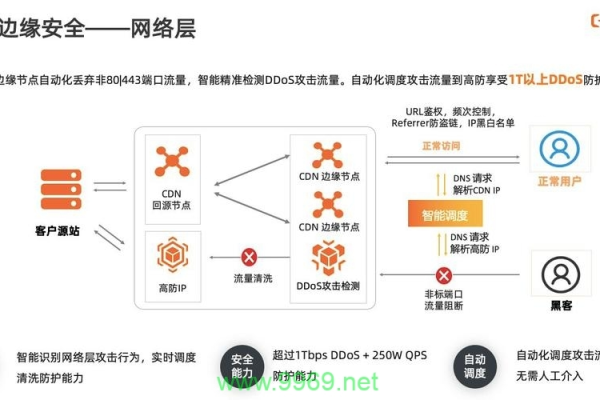
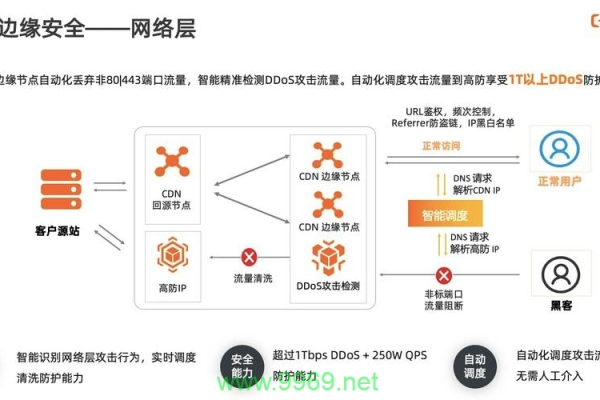
5、安全性保障
DDoS防护:通过分布式部署和流量清洗技术,有效防御DDoS攻击。
数据加密:使用SSL/TLS协议对传输的数据进行加密,保障数据安全。
访问控制:设置IP白名单和黑名单等访问控制策略,限制非规用户访问。
6、监控与优化
实时监控:监控系统的各项指标,如节点负载、响应时间和带宽使用,及时发现并处理问题。
故障排除:对出现故障的节点进行快速故障排除和恢复,确保系统正常运行。
性能优化:根据监控数据,持续优化缓存策略和负载均衡策略,提升系统性能。
7、案例分析
视频网站:通过智能DNS解析和内容缓存,将视频内容分发到离用户最近的节点,提升视频加载速度和播放流畅度。
电商平台:通过负载均衡和智能缓存,将用户请求分配到不同服务器,提高页面加载速度和用户访问体验。
在线教育平台:通过边缘计算和实时监控,减少直播课程的延迟,确保课程的稳定性和互动性。
8、前景展望
人工智能应用:引入人工智能技术,自动分析用户行为和需求,动态调整调度策略。
5G技术融合:随着5G技术的普及,进一步提升传输速度和响应时间,为用户带来更好的体验。
边缘计算发展:随着边缘计算技术的发展,CDN调度将更加依赖边缘计算,进一步减少延迟,提升用户体验。
以下是两个关于CDN视频调度的常见问题及其解答:
1、什么是CDN视频调度的核心目标?
核心目标:CDN视频调度的核心目标是通过优化内容传输路径和方式,提升视频传输的速度和稳定性,从而改善用户的观看体验,这包括减少视频加载时间、提高播放流畅度、降低卡顿率以及确保视频内容的高质量传输。
2、CDN视频调度如何应对网络波动和突发流量?
应对网络波动:CDN视频调度通过实时监控网络状况,动态调整传输路径和缓存策略,以应对网络波动,当检测到某条路径的网络延迟增加或丢包率上升时,系统会自动切换到更稳定的路径,或者增加冗余数据传输,以确保视频流的连续性和稳定性。
应对突发流量:CDN视频调度具备强大的负载均衡能力,能够将突发流量分散到多个服务器或节点上,避免单一节点过载导致的服务中断,通过智能缓存和预取技术,提前将热门视频内容缓存到靠近用户的节点上,减少源服务器的压力,提高整体系统的响应速度和稳定性,CDN还可以根据历史数据和预测模型,提前准备资源以应对可能的突发流量高峰。
小编有话说:CDN视频调度作为现代互联网基础设施的重要组成部分,不仅提升了视频传输的效率和稳定性,还极大地改善了用户的观看体验,随着技术的不断进步和应用的深入,CDN视频调度将在更多领域发挥重要作用,为用户提供更加流畅、高质量的视频服务。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20