如何利用XP系统搭建自己的邮件服务器?

建立邮件服务器是一个复杂的过程,需要一定的网络知识和系统管理技能,在Windows XP上设置一个邮件服务器可能不是最佳选择,因为Windows XP是一个相对老旧的操作系统,且微软已于2014年停止对其的支持,如果你仍然需要在Windows XP上建立一个邮件服务器,以下是一些基本步骤和考虑因素。
准备工作
1、系统要求:确保你的Windows XP系统满足邮件服务器软件的最低要求。
2、域名:你需要一个域名来接收和发送电子邮件。
3、网络设置:确保你的网络设置允许邮件服务器通信(端口25用于SMTP,端口110或143用于POP3/IMAP)。
选择合适的邮件服务器软件
| 软件名称 | 描述 |
| hMailServer | 一个免费的、开源的邮件服务器,支持Windows平台。 |
| Mercury Mail Server | 另一个免费的邮件服务器,也支持Windows XP。 |
安装和配置邮件服务器软件
以hMailServer为例:
1、下载和安装:从官方网站下载hMailServer,并按照安装向导进行安装。
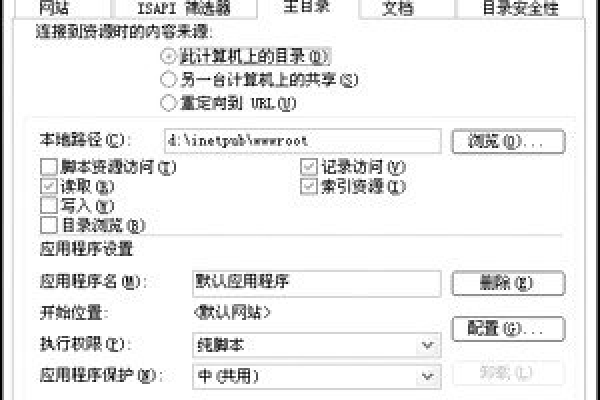
2、配置域名和IP地址:在hMailServer中设置你的域名和服务器的IP地址。
3、创建域:添加一个新的域,输入你的域名信息。
4、添加用户:为你的域添加用户账户,设置用户名和密码。
5、设置协议:配置SMTP、POP3和IMAP协议,确保它们正确工作。
6、安全设置:配置TLS/SSL加密,以提高安全性。
7、测试:发送和接收测试邮件,确保一切正常工作。
防火墙和路由器设置
确保你的防火墙和路由器允许邮件服务器的通信,你可能需要开放以下端口:
SMTP (端口25)
POP3 (端口110) 或 IMAP (端口143)
如果使用SSL,则还需要开放465 (SMTP SSL) 和993/995 (IMAP/POP3 SSL)
维护和监控
定期更新:保持邮件服务器软件的更新,以修补安全破绽。
备份:定期备份邮件数据和配置。
监控:监控服务器的性能和安全性,确保没有未授权的访问。
相关问题与解答
Q1: 在Windows XP上使用邮件服务器安全吗?
A1: 由于Windows XP已经不再接收官方的安全更新和支持,运行任何服务,包括邮件服务器,都存在较高的安全风险,建议升级到更新的操作系统,如Windows 10或Linux发行版,这些系统提供更好的安全性和性能。
Q2: 如果我想在现代操作系统上建立邮件服务器,应该选择哪个?
A2: 对于现代操作系统,Linux发行版(如Ubuntu Server、CentOS)是流行的选择,因为它们提供了强大的社区支持和大量的文档,Linux系统通常被认为比Windows更安全,更适合作为服务器操作系统,如果你偏好Windows环境,可以考虑使用Windows Server系列,它们提供了更多的服务器功能和更好的支持。
以上就是关于“xp建立邮件服务器_邮件”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/144865.html