什么是CDN视频加速技术,它如何提升用户体验?

在现代互联网环境中,搭建视频CDN(内容分发网络)已经成为确保视频内容快速、稳定分发的关键,通过选择合适的CDN服务提供商、优化视频内容、配置服务器和网络架构、选择流媒体协议以及监控和优化网络性能等步骤,可以构建一个高效的视频CDN系统。
一、选择合适的CDN服务提供商
选择一个合适的CDN服务提供商是搭建视频CDN的第一步,CDN服务提供商会提供分布在全球的服务器网络,用来缓存和分发视频内容,以下是几个重要的考虑因素:
1、覆盖范围:确保CDN服务提供商在目标用户所在的区域拥有足够的服务器节点,覆盖范围越广,用户体验越好,大多数顶级的CDN服务提供商,如Cloudflare、Akamai、Amazon CloudFront和Google Cloud CDN,都在全球范围内拥有广泛的服务器网络。
2、性能和可靠性:检查CDN服务提供商的性能和可靠性,可以参考第三方性能评测报告,或者进行试用评测,关键指标包括延迟、带宽和缓存命中率等。
3、成本:成本是一个重要的考虑因素,不同CDN服务提供商的定价模式有所不同,有的按流量计费,有的按请求次数计费,需要根据视频流量和预算来选择最合适的方案。
4、客户支持:良好的客户支持是保障服务顺利运行的重要因素,确保CDN服务提供商提供24/7的技术支持,并且响应速度快。
优化视频内容是搭建视频CDN的重要环节,确保视频在传输过程中占用最少的带宽,同时保持高质量。
1、视频编码:选择合适的视频编码格式,如H.264、H.265或VP9等,H.265和VP9相较于H.264能提供更高的压缩效率,减少带宽占用,但编码和解码的计算资源需求较高。
2、视频分辨率和比特率:根据用户设备和网络状况,提供不同分辨率和比特率的多版本视频文件,可以提供1080p、720p和480p的版本,用户可以根据网络状况自动选择最合适的版本。
3、视频片段化:将视频文件分割成小片段,可以提高缓存效率和用户体验,常见的片段化格式包括HLS(HTTP Live Streaming)和DASH(Dynamic Adaptive Streaming over HTTP)。

三、配置服务器和网络架构
配置服务器和网络架构是搭建视频CDN的核心步骤,确保视频内容能够快速、稳定地传输到用户端。
1、原始服务器配置:原始服务器是存储视频内容的源服务器,需要具备高性能和高可靠性,确保原始服务器具备足够的存储空间、带宽和处理能力。
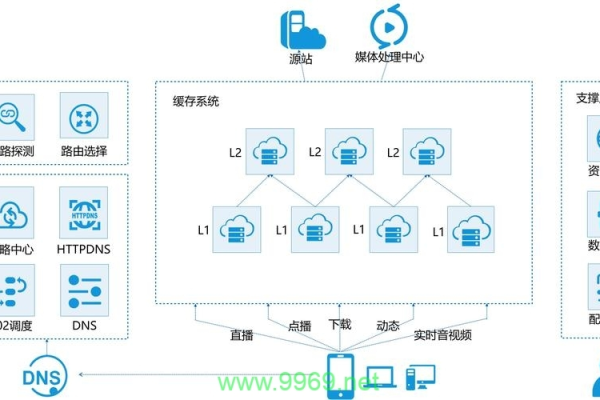
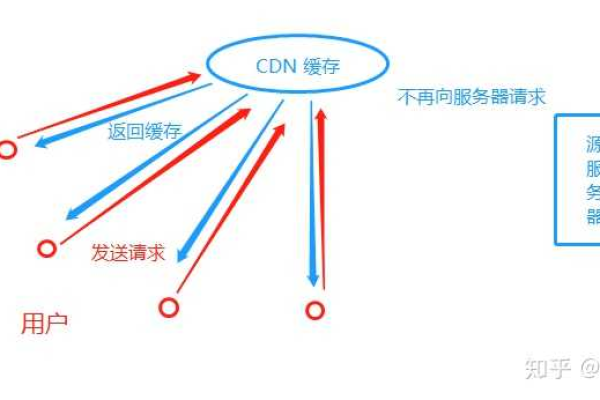
2、边缘服务器配置:边缘服务器是CDN网络的关键组成部分,负责缓存和分发视频内容,确保边缘服务器分布在靠近用户的地理位置,以降低延迟。
3、负载均衡:使用负载均衡技术,将用户请求分配到不同的边缘服务器上,确保服务器负载均匀,避免单点故障,常见的负载均衡算法包括轮询、最少连接和IP哈希等。
四、进行流媒体协议选择
流媒体协议是视频传输的基础,选择合适的协议可以提高传输效率和用户体验。
1、HTTP Live Streaming (HLS):HLS是由Apple开发的一种流媒体协议,广泛应用于iOS和macOS设备,HLS将视频文件分割成小片段,通过HTTP协议传输,具有良好的兼容性和适应性。
2、Dynamic Adaptive Streaming over HTTP (DASH):DASH是另一种常见的流媒体协议,由MPEG组织开发,DASH和HLS类似,采用自适应码率技术,根据网络状况动态调整视频质量。

3、Real-Time Messaging Protocol (RTMP):RTMP是由Adobe开发的一种流媒体协议,广泛应用于实时直播场景,RTMP具有低延迟、高实时性的特点,但对网络环境要求较高。
五、监控和优化网络性能
监控和优化网络性能是确保视频CDN稳定运行的重要步骤,通过实时监控网络状况,及时发现并解决问题,可以大幅提高用户体验。
1、网络监控工具:使用网络监控工具,如Pingdom、New Relic和Datadog等,实时监控服务器和网络状况,监控指标包括延迟、带宽、缓存命中率和错误率等。
2、性能优化策略:根据监控数据,采取相应的性能优化策略,优化视频内容缓存策略、调整负载均衡算法、扩展服务器容量等。
3、用户反馈:收集用户反馈,了解用户在使用过程中遇到的问题和需求,根据用户反馈,持续改进和优化视频CDN。
六、其他重要考虑因素
除了上述关键步骤,还有一些其他重要的考虑因素,可以帮助您搭建一个更加完善的视频CDN。
1、安全性:确保视频内容的安全性,防止未经授权的访问和复刻,可以使用HTTPS协议加密传输、设置访问控制策略、启用防火墙和DDoS防护等措施。

2、法律法规:遵守相关法律法规,确保视频内容的合法性,遵守版权法、隐私保护法和数据保护法等。
3、可扩展性:确保视频CDN具备良好的可扩展性,能够应对未来的业务增长,可以通过增加服务器节点、扩展带宽和存储容量等方式,实现系统的弹性扩展。
七、案例分析
通过实际案例分析,可以更好地理解视频CDN的搭建过程和要点,以下是一些成功的视频CDN搭建案例:
1、Netflix:Netflix是全球领先的视频流媒体服务提供商,通过搭建自有CDN(Open Connect),实现了高效的视频内容分发,Netflix的Open Connect网络由数千台专用服务器组成,分布在全球各地的ISP(互联网服务提供商)数据中心,确保用户可以快速、稳定地观看视频内容。
2、YouTube:YouTube是全球最大的视频分享平台,依靠Google的全球CDN网络,实现了海量视频内容的高效分发,YouTube采用了多种优化技术,包括视频编码优化、缓存策略优化和自适应码率技术,确保用户在各种网络环境下都能获得良好的观看体验。
3、Hulu:Hulu是美国知名的视频流媒体服务提供商,通过与多家CDN服务提供商合作,构建了高效的视频CDN网络,Hulu采用了多CDN策略,根据网络状况和用户位置,动态选择最优的CDN服务提供商,确保视频内容的快速、稳定分发。
搭建视频CDN是一个复杂的过程,需要综合考虑多个因素,包括CDN服务提供商选择、视频内容优化、服务器和网络架构配置、流媒体协议选择、网络性能监控和优化等,通过遵循上述步骤,结合实际业务需求和用户反馈,可以构建一个高效、稳定的视频CDN,提供优质的用户体验。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20