竞信CDN是什么,它有哪些特点和优势?

上海竞信网络科技有限公司获得CDN牌照,业务覆盖广东、上海和北京。该公司专注于信息化整合解决方案,提供IPTV和CDN服务。
竞信CDN是上海竞信网络科技有限公司旗下的内容分发网络(Content Delivery Network,简称CDN)服务,竞信网络成立于2006年,是一家专注于应用软件开发和系统集成的企业,致力于为政府和企事业单位提供优秀的信息化整合解决方案和专业的技术咨询服务,竞信网络获得了工信部颁发的内容分发网络业务经营许可证(即CDN牌照),业务范围覆盖广东省、上海市和北京市。
竞信CDN的核心优势
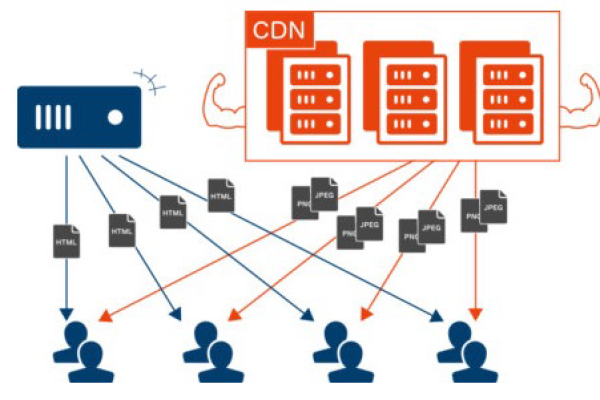
竞信CDN拥有在全国布建服务节点的能力,能够实现全国范围内的数据内容加速,开辟了一条总量庞大、分布均匀,数据传输距离可近至1公里的网络加速通道,这种布局不仅提高了数据传输的效率,还大大减少了延迟,提升了用户体验。
竞信CDN的应用场景
竞信CDN广泛应用于各种需要高速度和低延迟的场景,
1、网站加速:通过在多个地点缓存网站内容,减少用户访问时的加载时间。
2、视频流媒体:支持高清视频的流畅播放,减少卡顿现象。
3、游戏服务:降低游戏延迟,提供更流畅的游戏体验。
4、移动应用:加速移动应用的内容交付,提高用户满意度。
竞信网络的股东结构
竞信网络的最大股东是董静颐,出资比例达到80.00%,她的合作伙伴王金高出资比例为20.00%,这种股权结构确保了公司在决策和运营上的稳定。
竞信网络的市场地位
作为一家高新技术企业和双软认证企业,竞信网络在业内享有较高的声誉,其CDN解决方案被广泛应用于各类企业和机构,帮助它们应对日益增长的数据流量和复杂的网络需求。
竞信网络的未来展望
随着互联网技术的不断发展,竞信网络将继续优化其CDN服务,提升技术水平,扩大服务范围,公司还计划进一步拓展国际市场,与全球更多的企业和机构合作,共同推动互联网技术的发展和应用。
竞信CDN凭借其强大的技术实力和优质的服务,已经成为众多企业和机构的首选CDN服务提供商,竞信网络将继续努力,为客户提供更加高效和稳定的网络加速服务。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11