
上一篇
如何使用MapReduce处理气温数据以预测心知天气?
MapReduce是一种编程模型,用于处理和生成大数据集。在这个例子中,我们使用MapReduce来计算心知天气的气温数据。我们将 气温数据分成多个小文件,然后使用Map函数对每个文件进行处理,最后通过Reduce函数将所有结果合并。
在当今大数据时代,处理和分析庞大的数据集已成为一种常态,MapReduce,作为一种编程模型,广泛用于大规模数据处理,将通过“气温_心知天气”案例深入探讨MapReduce的应用。
MapReduce基础
MapReduce模型主要由两部分组成:Map(映射)和Reduce(归约),简单地说,Map负责将复杂的任务分解为多个简单的子任务,而Reduce则负责汇总这些子任务的结果得到最终结果,这种模型非常适合于并行处理大量数据,提高处理速度。
案例背景与需求
在这个案例中,需要处理的是1901年和1902年的天气源数据,具体任务是找出这两年内每天的最高温度和最低温度,这项任务看似简单,但考虑到数据的规模和复杂性,直接处理非常耗时且效率低下,采用MapReduce模型进行处理。
Map阶段设计
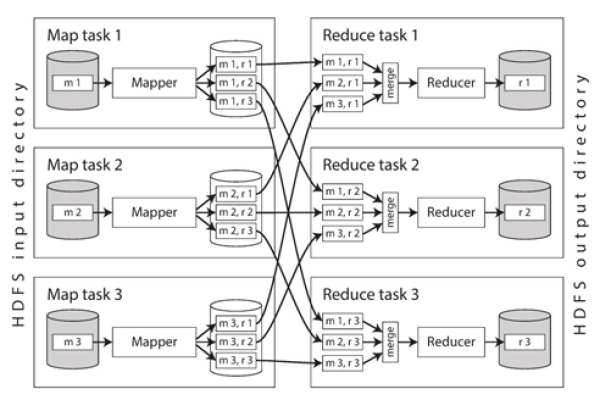
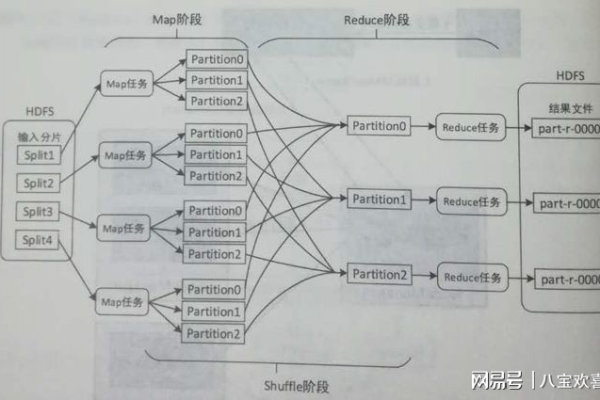
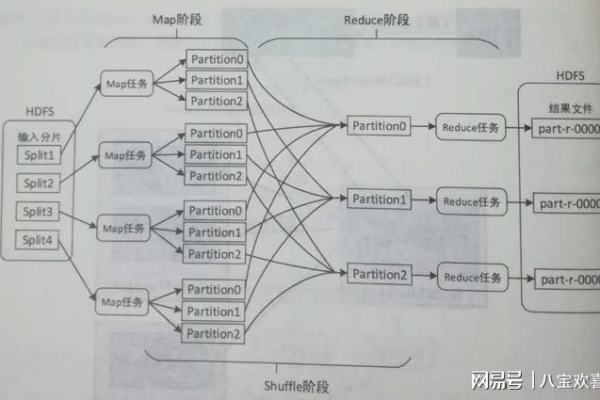
Map函数需要读取原始的天气数据,这些数据通常以文本文件的形式存储,每一行代表一条天气记录,包含日期、温度等信息,Map函数的任务是解析每条记录,提取出日期和温度,然后以日期为键(key),温度为值(value)输出中间结果。
在这个过程中,每个Map任务只处理输入数据的一个子集,这样可以在多台机器上并行执行,显著提高效率。
Reduce阶段设计
Reduce阶段的工作是将Map阶段的输出整合起来,由于Map阶段的输出中,同一日期的温度可能被多个Map任务处理,Reduce函数需要对这些温度进行比较,找出每一天的最高温度和最低温度。
在Reduce阶段,每个Reduce任务都会接收到特定日期的所有温度值,然后通过比较逻辑找出极值,所有Reduce任务的输出合并起来,就得到了整个数据集每天的最高温度和最低温度。
实现细节
MrTemperature.java是这个案例的主要Java源代码文件,它包含了Map和Reduce的具体实现,在编码过程中,开发者需要关注数据的读取、解析以及如何高效地进行数据的分发和聚合。
为了优化性能,可以在Map阶段使用combining技术,即将Map输出的键值对在本地先进行一次小范围的Reduce操作,减少数据的网络传输量,选择合适的数据结构对于提高数据处理速度也至关重要。
集群配置和运行
要运行这个MapReduce作业,首先需要设置好Hadoop集群环境,这包括了Hadoop的安装、配置以及集群的搭建,具体的操作步骤可以参考相关教程,完成设置后,就可以通过Hadoop的命令行工具提交MapReduce作业并监控其运行状态。
通过“气温_心知天气”这个案例,可以清晰地看到MapReduce在处理大规模天气数据集中的强大能力,从数据的预处理、Map和Reduce函数的设计,到最终的结果输出,每一步都体现了MapReduce在数据处理领域的高效性和实用性。
FAQs
1. Q: 如果数据量继续增加,MapReduce作业的性能会如何变化?
A: 数据量的增加会影响MapReduce作业的运行时间,因为更多的数据意味着更多的Map和Reduce任务需要处理,由于MapReduce的设计允许任务在多台机器上并行执行,合理的集群扩展可以有效地处理更大规模的数据,也要注意管理好网络传输量和磁盘I/O,因为它们可能成为新的瓶颈。
2. Q: 如何优化MapReduce作业的性能?
A: 优化MapReduce作业的性能可以从以下几个方面考虑:
合理设置Map和Reduce的数量:根据集群的大小和数据的特性调整Map和Reduce任务的数量,以达到最佳的负载均衡。
启用Combing和压缩:Combing可以在Map阶段本地减少数据量,而数据压缩可以减少数据传输和存储的成本。
优化数据存储格式:使用如SequenceFile等高效的数据存储格式可以提高读写效率。
代码优化:优化Map和Reduce函数的代码,避免不必要的计算和数据访问。
硬件升级:提升硬件配置,如增加内存、使用更快的硬盘等,也可以提高作业的执行速度。
通过上述措施,可以有效提升MapReduce作业的处理能力和效率,应对更大规模的数据处理需求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/144224.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
MapReduce处理数据时,如何有效执行MapReduce Action?
-
如何使用MapReduce处理HBase 1.2中的数据?
-
如何使用Java MapReduce API来掌握MapReduce编程?
-
Morphia MapReduce: 如何有效使用MongoDB的MapReduce功能?
-
如何理解和使用MapReduce中的cmdenv_MapReduce命令?
-
如何通过MapReduce REST API接口管理MapReduce作业?
-
MapReduce解决方案,如何通过MapReduce技术解决大数据处理难题?
-
MapReduce与Bigtable_MapReduce,如何协同工作以优化大数据处理?
-
MapReduce框架在数据处理中的应用特点有哪些?如何进行MapReduce应用开发?
-
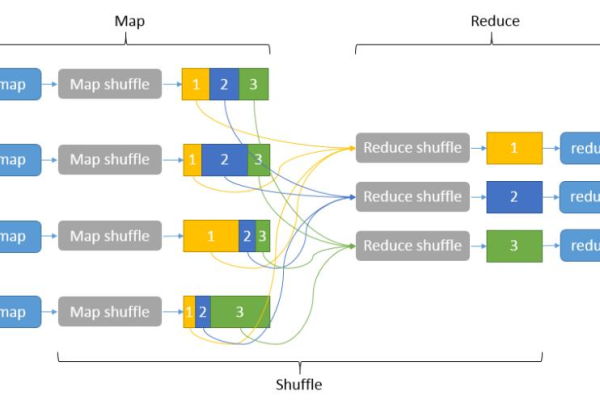
MRS MapReduce中MapReduce节点如何实现高效数据处理的优化策略?
-
MapReduce 的双轮驱动,如何有效利用两个 MapReduce 任务进行数据处理?
-
MapReduce中的catchfile_MapReduce是如何优化数据处理的?
-
MapReduce分析_MapReduce: 探索数据处理的未来?
-
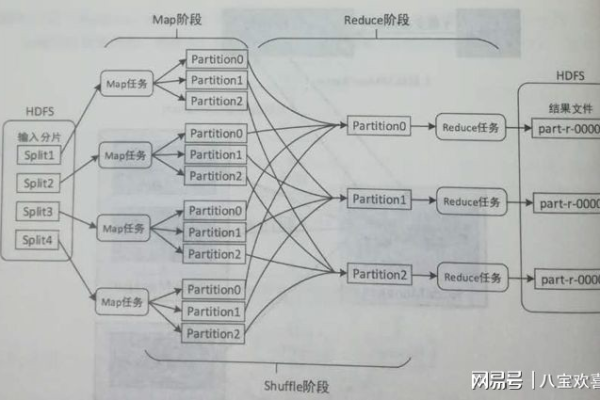
MapReduce输入输出,在MapReduce应用开发中,有哪些关键概念决定了数据的输入与输出处理流程?
-
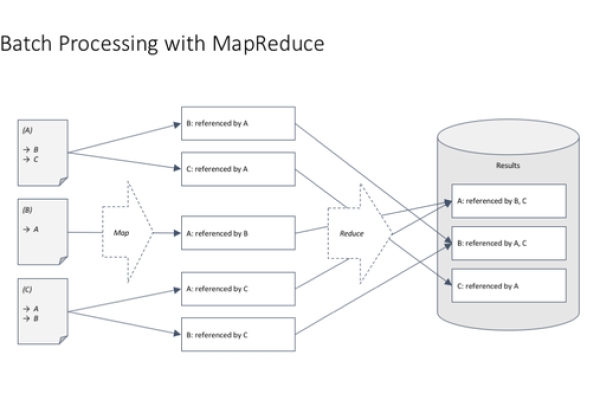
如何利用MapReduce框架实现数据统计?探索MapReduce统计样例代码!
-
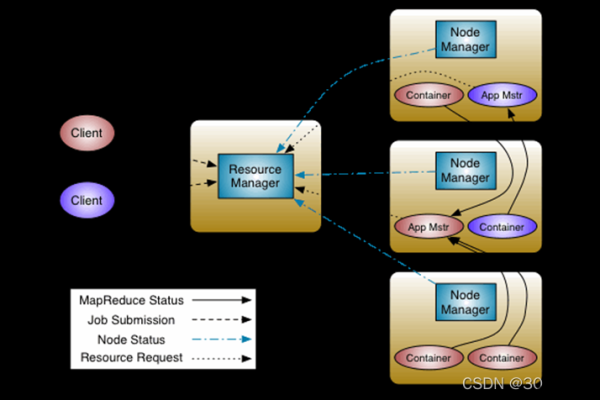
MapReduce技术中的Redie阶段如何影响整个MapReduce工作流程的效率?
-
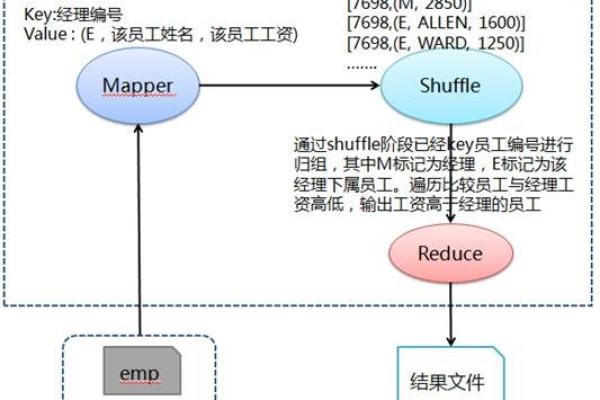
MapReduce文本对处理,探索TextPair_MapReduce的实际应用与挑战
-
为何在MapReduce处理中,复合Key的复合查询能够有效提升数据处理效率?
-
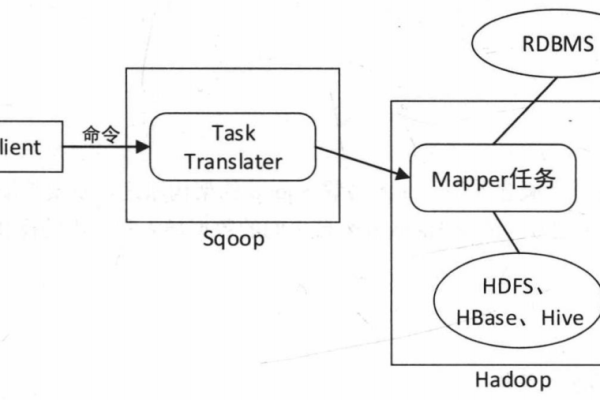
在多个MapReduce串联和多个NameService环境下,MapReduce任务失败的原因是什么?