如何掌握MySQL教程并有效使用它?

MySQL教程_使用教程
MySQL作为一种广泛使用的关系型数据库管理系统,其基本操作包括数据库和数据表的创建、数据的插入与查询、数据更新与删除等,以下是一个详细的MySQL使用教程,涵盖从连接到MySQL服务器到执行各种数据库操作的步骤。
连接到MySQL服务器
在使用MySQL之前,需要先连接到MySQL服务器,可以使用命令行工具(如MySQL Shell或终端)或图形化工具(如phpMyAdmin),以下是使用命令行工具连接到MySQL服务器的示例:
mysql -u root -p
系统会提示输入密码,输入正确的密码后即可连接到MySQL服务器。
创建和删除数据库
2-1创建数据库
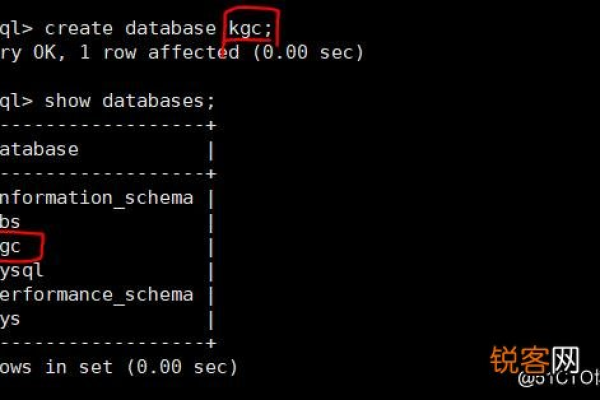
在MySQL中,可以使用CREATE DATABASE语句来创建数据库,以下是创建一个名为my_database的数据库的示例:
CREATE DATABASE my_database;
执行上述语句后,MySQL将创建一个名为my_database的数据库,如果要查看所有数据库,可以使用SHOW DATABASES语句:
SHOW DATABASES;
2-2删除数据库
使用DROP DATABASE语句来删除数据库,语法如下:
DROP DATABASE my_database;
注意:删除数据库是一个危险操作,因为它将永久删除数据库及其包含的所有数据表和数据,在执行此操作之前,请确保已经备份了重要的数据。
数据表操作
3-1选择数据库
在创建数据表之前,需要先选择要在其中创建数据表的数据库,使用USE语句来选择数据库,语法如下:
USE my_database;
3-2创建数据表
使用CREATE TABLE语句来创建数据表,语法如下:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
)engine = innodb default charset = utf-8; 示例创建了一个名为users的数据表,包含id、name和email三个列。
3-3查询数据表
使用SELECT语句来查询数据表中的数据,语法如下:
SELECT * FROM users;
3-4修改数据表
使用ALTER TABLE语句来修改数据表的结构,例如增加列:
ALTER TABLE users ADD COLUMN age INT;
3-5删除数据表

使用DROP TABLE语句来删除数据表,语法如下:
DROP TABLE users;
4-1插入数据
使用INSERT INTO语句来向数据表中插入数据,语法如下:
INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com'); 4-2查询数据
除了基本的SELECTFROM users;查询外,还可以使用WHERE条件查询特定数据
SELECT * FROM users WHERE id = 1;
4-3更新数据
使用UPDATE语句来更新数据表中的数据,语法如下:
UPDATE users SET email = 'newemail@example.com' WHERE id = 1;
4-4删除数据
使用DELETE FROM语句来删除数据表中的数据,语法如下:
DELETE FROM users WHERE id = 1;
统计函数
MySQL提供了多种统计函数,用于对数据进行汇总和分析,以下是一些常见的统计函数:
5-1COUNT()函数
COUNT()函数用于统计行数,语法如下:
SELECT COUNT(*) FROM users;
5-2AVG()函数

AVG()函数用于计算平均值,语法如下:
SELECT AVG(age) FROM users;
5-3SUM()函数
SUM()函数用于计算总和,语法如下:
SELECT SUM(age) FROM users;
5-4MAX()和MIN()函数
MAX()和MIN()函数分别用于获取最大值和最小值,语法如下:
SELECT MAX(age), MIN(age) FROM users;
联合查询
6-1内连接
内连接用于返回两个表中匹配的记录,语法如下:
SELECT A.*, B.* FROM table1 AS A INNER JOIN table2 AS B ON A.common_field = B.common_field;
6-2外连接
外连接用于返回左表或右表中的所有记录,语法如下:
SELECT A.*, B.* FROM table1 AS A LEFT JOIN table2 AS B ON A.common_field = B.common_field;
6-3子嵌套查询
子查询可以嵌套在其他查询中,语法如下:
SELECT * FROM table1 WHERE common_field IN (SELECT common_field FROM table2);
窗口函数
窗口函数用于在查询结果集中生成计算列,以下是一些常用的窗口函数:
7-1序号函数

ROW_NUMBER()函数为每一行分配一个唯一的序号,语法如下:
SELECT *, ROW_NUMBER() OVER (ORDER BY id) AS row_num FROM users;
7-2分布函数
NTILE(N)函数将结果集分为N个部分,语法如下:
SELECT *, NTILE(4) OVER (ORDER BY id) AS tile FROM users;
7-3前后函数
LAG()和LEAD()函数分别用于获取前一行和后一行的值,语法如下:
SELECT *, LAG(age) OVER (ORDER BY id) AS previous_age, LEAD(age) OVER (ORDER BY id) AS next_age FROM users;
7-4头尾函数
FIRST_VALUE()和LAST_VALUE()函数分别用于获取第一个和最后一个值,语法如下:
SELECT FIRST_VALUE(age) OVER (ORDER BY id) AS first_age, LAST_VALUE(age) OVER (ORDER BY id) AS last_age FROM users;
FAQs相关问题解答
Q1:如何更改MySQL数据库的密码?
A1:要更改MySQL数据库的密码,可以使用以下SQL语句:
ALTER USER 'username'@'hostname' IDENTIFIED BY 'newpassword'; FLUSH PRIVILEGES;
Q2:如何在MySQL中备份和恢复数据库?
A2:在MySQL中,可以使用mysqldump命令备份数据库,使用mysql命令恢复数据库,备份数据库的命令如下:
mysqldump -u root -p database_name > backup_file.sql
恢复数据库的命令如下:
mysql -u root -p database_name < backup_file.sql
小编有话说
通过本教程,你已经掌握了MySQL的基本使用方法,包括数据库和数据表的创建、数据的增删改查、以及常见的统计函数和联合查询,希望这些知识能帮助你在日常工作中更好地管理和操作MySQL数据库,如果你有任何疑问或建议,欢迎在评论区留言讨论!




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01