
上一篇
如何在HBase 0.96版本中集成MapReduce服务以优化数据处理?
MapReduce是一个用于大规模数据处理的编程模型,HBase 0.96是其一个版本。MRS代表MapReduce服务,它是处理大数据集的计算框架,常与Hadoop生态系统中的HBase数据库一起使用以提升性能和效率。
探索MapReduce HBase 0.96_MapReduce服务 MRS的集成与优化

在大数据时代,数据处理和分析成为企业获取洞见、优化决策的关键,HBase作为一个分布式、可伸缩的大数据存储系统,配合MapReduce这一高效的数据处理框架,提供了卓越的数据操作能力,本文将深入探讨MapReduce HBase 0.96版本中的MapReduce服务(MRS),其特点、实现方式及应用实例,旨在为相关领域的专业人士提供技术参考和实践指南。
MapReduce HBase 0.96的核心价值在于其能够高效地处理和分析存储在HBase中的大规模数据集,通过整合HBase的分布式存储特性和MapReduce的并行计算能力,该系统能够在较短的时间内完成复杂的数据处理任务,这种整合的优势不仅体现在速度上,还包括了高度的可扩展性和容错性,使得系统能够适应快速增长的数据量和复杂的数据处理需求。
在技术实现层面,MapReduce HBase 0.96的一个关键特点是其对HBase的深度整合,开发者需要确保所有必要的依赖项在本地CLASSPATH可用,这些依赖项最终会被打包并部署到MapReduce集群中,这一过程可以通过传递全量的HBase classpath(包括独立的jars和配置)来实现,确保MapReduce作业能够无缝地调用HBase的相关功能,从源码层面上看,TableMapReduceUtil#addDependencyJars(org.apache.hadoop.mapreduce.Job)方法的具体实现也展示了如何将HBase的类路径动态添加到MapReduce作业配置中,进一步增强了两者之间的互操作性。
对于性能的提升,MapReduce HBase 0.96显著优化了数据处理的速度和稳定性,该版本修复了超过2000个问题,包括提升了系统的运行时稳定性、可操作性和伸缩性,这些改进直接反映在数据处理的效率上,使得系统能够更快地响应复杂的查询请求,同时保持较低的错误率。
在应用场景方面,MapReduce HBase 0.96可以支持多种数据处理任务,从简单的数据导入导出到复杂的数据分析和转换,通过使用HBase的相关Java API,开发者可以方便地实现伴随HBase操作的MapReduce过程,这包括但不限于从本地文件系统导入数据到HBase表中,或从HBase读取原始数据后使用MapReduce进行数据分析。
在使用过程中也可能遇到一些挑战,在开发过程中必须注意作业的配置和优化,以确保达到最佳的执行效率,对于初级开发者而言,理解和运用MapReduce模型本身可能存在一定的难度,需要通过实践和学习来逐步掌握。
针对上述内容,以下是一些常见问题及其解答,旨在进一步澄清概念并解决实际应用中的疑惑:
FAQs
Q1: MapReduce HBase 0.96在处理大数据集时有哪些优势?
A1: MapReduce HBase 0.96在处理大数据集时的主要优势包括:
高效的数据处理:结合HBase的分布式存储和MapReduce的并行计算能力,加速数据处理过程。
高可扩展性:能够适应不断增长的数据量,通过增加节点轻松扩展计算和存储能力。
强大的容错机制:自动处理节点故障,确保数据处理任务的顺利完成。
Q2: 如何解决MapReduce HBase 0.96中的类路径依赖问题?
A2: 解决类路径依赖问题的方法主要包括:
确保依赖项可用:所有必要的依赖项必须在本地CLASSPATH中可用。
使用全量HBase classpath:传递全量的HBase classpath(包括独立的jars和配置)到MapReduce作业运行器中。
利用TableMapReduceUtil工具:使用TableMapReduceUtil#addDependencyJars(org.apache.hadoop.mapreduce.Job)方法来动态添加依赖项到作业配置中。
通过上述措施,可以有效地解决依赖问题,保证MapReduce作业的顺利执行。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/144073.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
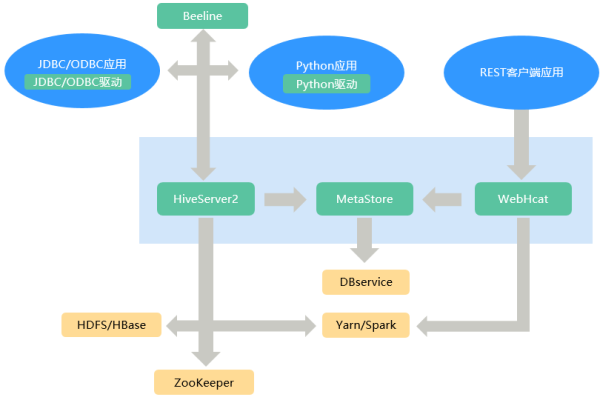
MRS_MapReduce服务是什么?如何利用Mapreduce服务MRS进行数据处理?
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
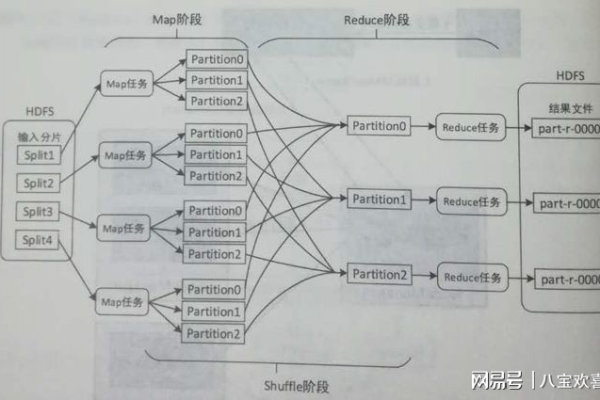
MapReduce与Bigtable_MapReduce,如何协同工作以优化大数据处理?
-
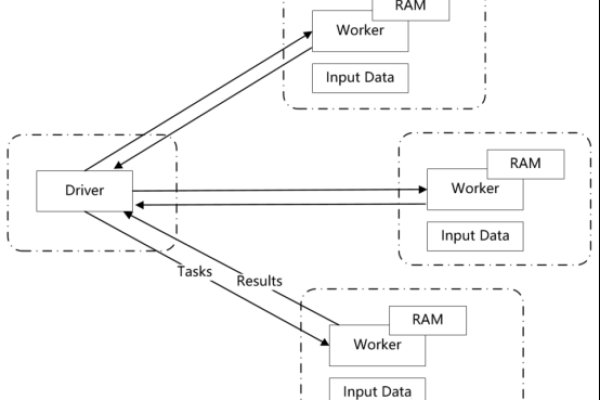
在分布式计算领域,MapReduce和Spark作为两种流行的大数据处理框架,它们在设计哲学、性能优化以及易用性方面存在显著差异。特别是当涉及到华为云的DLI(数据湖探索)服务中的Spark组件与华为云MRS(MapReduce服务)中的Spark组件时,用户可能会好奇这两者之间的具体区别是什么?
-
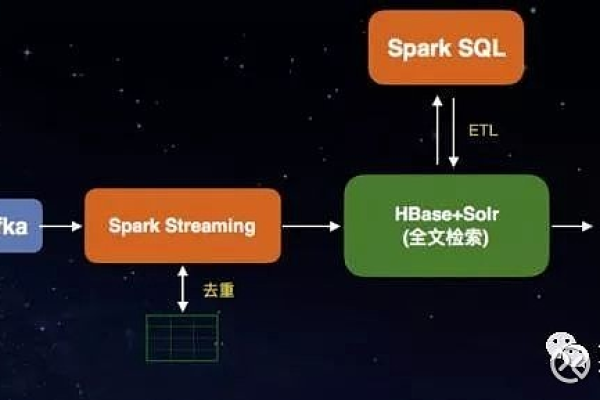
如何将MapReduce服务与HBase集成以提高数据处理效率?
-
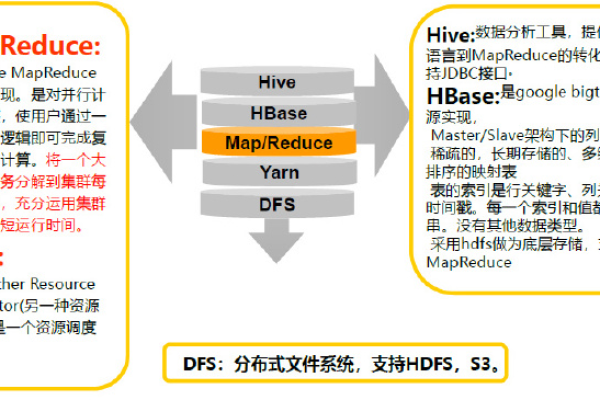
如何整合MapReduce和HBase以优化数据处理效率?
-
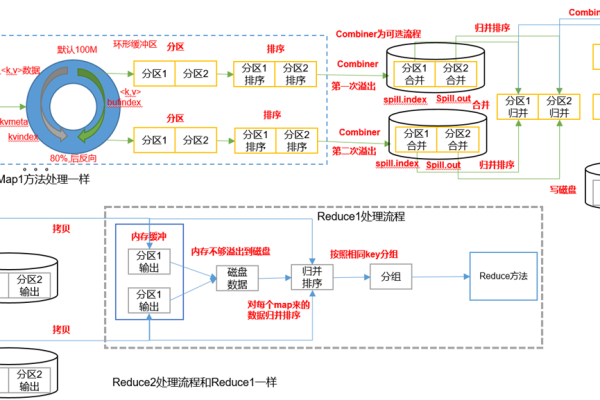
如何将MapReduce与HBase整合以优化数据处理流程?








