
上一篇
如何利用MapReduce技术高效地查询数据库?
MapReduce是一种编程模型,用于处理和生成大数据集。它包括两个主要阶段:Map阶段将输入数据分成多个小任务并行处理;Reduce阶段则汇总这些任务的结果得到最终输出。在数据库查询中,MapReduce可用来优化复杂查询的执行效率。
MapReduce模型和关系型数据库在数据存储与处理方面扮演着至关重要的角色,关系型数据库广泛用于数据存储和检索,而MapReduce模型则擅长处理大规模数据集,下面将深入探讨如何结合使用MapReduce与数据库技术,实现高效的数据处理解决方案:

设计MapReduce作业与数据库交互
当需要从数据库读取数据进行MapReduce处理时,可以设计一个MapReduce作业,其中Mapper负责从数据库中读取数据,这通常涉及以下步骤:
1、连接配置: 配置数据库连接参数,确保MapReduce作业能够顺利连接到数据库。
2、数据读取: 利用Map函数逐行读取数据库表中的数据,并将其转换为键值对形式供后续处理。
3、数据处理: 在Map阶段完成数据的初步筛选和转换,为Reduce阶段准备数据。
4、结果写入: 最终的处理结果可以通过Reduce函数写回数据库,或存储到其他指定的存储系统中。
创建实体类与数据库表映射
为了在MapReduce作业中操作数据库表,需要创建相应的实体类,这些实体类需要继承Writable和DBWritable类,并重写它们的序列化和反序列化方法,对于一个名为Goods的数据库表,可以创建一个名为GoodsBean的实体类,如下所示:
public class GoodsBean implements DBWritable, Writable {
private String id; // 商品ID
private String name; // 商品名称
// ... 更多字段
// getter和setter方法
// 重写write和readFields方法
}通过这种方式,MapReduce作业可以方便地与数据库表进行数据交换。
实现Map与Reduce阶段
在Map阶段,可以编写一个Mapper类来执行数据库查询,并将结果转换为键值对,Mapper的输入是数据库中的原始数据,输出则是经过处理的键值对集合,这些键值对作为Reduce阶段的输入,由Reducer进一步处理以生成最终的聚合结果。
优化数据库操作性能
在大数据场景下,直接从数据库读取大量数据可能会导致性能问题,可以考虑以下优化措施:
1、分批读取: 将大量数据分成小块,逐步读取和处理,减轻内存压力。
2、索引优化: 对数据库表进行合理索引,加速查询速度。
3、缓存策略: 在适当情况下,使用缓存机制减少数据库访问次数。
通过上述措施,可以有效提升MapReduce与数据库交互的性能。
结合SQL与NoSQL数据库特点
对于结构化数据,传统的SQL数据库提供了强大的查询能力,而对于非结构化或半结构化数据,NoSQL数据库如Apache CouchBase使用MapReduce来完成数据查询,根据数据类型和处理需求,选择合适的数据库系统和查询方法,可以更高效地实现数据处理任务。
MapReduce模型与关系型数据库的结合使用,为处理大规模数据集提供了一种有效的解决方案,通过设计合理的MapReduce作业、创建实体类映射数据库表、实现Map和Reduce阶段的功能以及优化数据库操作性能,可以实现高效的数据存取和处理,根据数据的特点选择适合的数据库系统,也是提高数据处理效率的关键因素。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/142986.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
如何利用MapReduce技术高效地统计元数据的数量?
-
MapReduce技术中的Redie阶段如何影响整个MapReduce工作流程的效率?
-
如何利用MapReduce技术高效处理大规模图像数据?
-
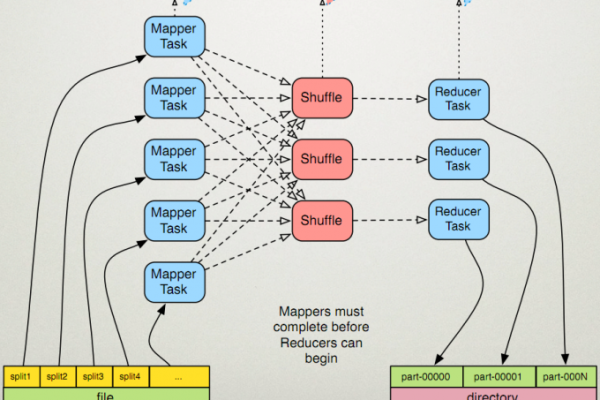
如何利用MapReduce技术高效提取特定数据集?
-
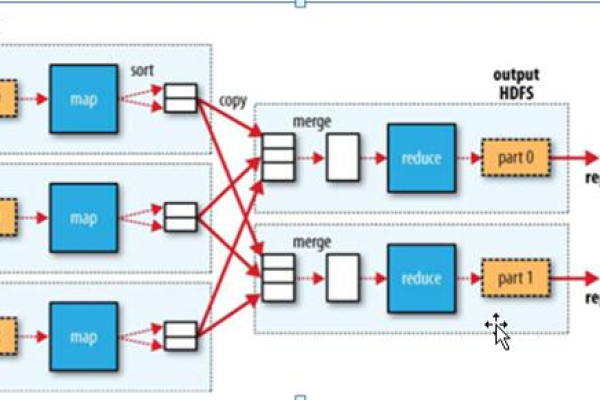
如何利用MapReduce技术高效统计事件数量?
-
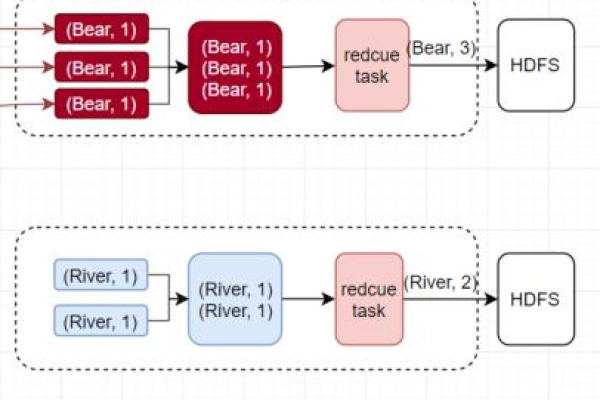
如何利用MapReduce技术高效构建字典?








