电脑网络驱动没了_电脑端

在数字化时代,网络连接已成为电脑使用中最为基础和关键的部分,当电脑的网络驱动出现问题时,用户的在线活动可能会受到严重影响,电脑网络驱动丢失不仅影响正常的上网活动,还可能导致与网络相关的其他功能失效,如网络打印、文件共享等,以下是面对这一情况时的解决步骤和注意事项:
1、检查硬件连接
确认网络设备完好:确保网线没有损坏,且正确连接到电脑的网络接口上。
检查硬件状态:查看网络适配器在设备管理器中是否被识别,有没有出现异常标识,如黄色感叹号。
2、通过网络诊断定位问题
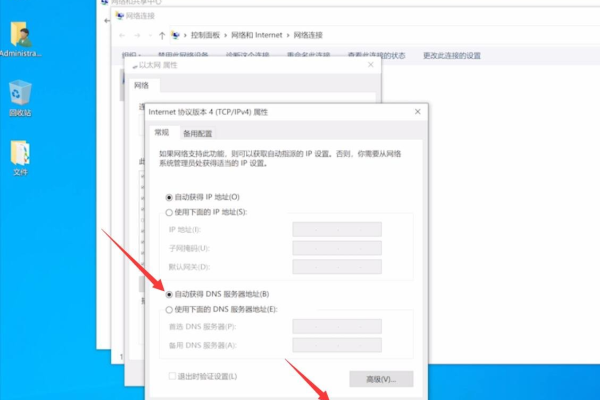
使用系统自带的网络诊断工具:Windows系统通常内置有网络诊断功能,可以帮助用户初步判断网络问题所在。
检查相关服务是否启动:确保网络相关的系统服务,如网络位置感知服务(NLA)和DHCP客户端等处于运行状态。
3、重新安装或更新网络驱动
使用有线连接修复无线驱动:如果无线网卡驱动丢失,可以先用有线网络连接下载并安装无线网卡的驱动。
利用外部存储介质传输驱动:在无网络的情况下,可通过U盘等外部存储设备,将网络驱动安装包从其他电脑拷贝过来进行安装。
4、利用软件工具修复驱动
第三方驱动管理软件:可以借助专业的第三方驱动管理软件,如“驱动总裁”等,进行驱动检测、下载和安装。
系统内置的解决方案:Windows系统更新和安全中的“故障排除”功能可能帮助修复一些常见的网络连接问题。
5、检查是否存在驱动冲突
检查驱动冲突:如果驱动更新后问题依旧存在,可能是新旧驱动之间或者不同驱动之间出现了冲突。
选择正确的驱动版本:确保下载和安装的驱动与你的系统版本(如Win10 64位)相匹配。
6、恢复系统或重置网络设置
系统还原:如果问题出现在最近的系统更新或软件安装之后,可以尝试使用系统还原功能恢复到之前的状态。
网络重置:在极端情况下,可以选择重置网络设置,但要注意这将导致所有网络配置丢失,需要重新配置。
在解决网络驱动问题的过程中,还需注意以下几点:
在进行任何操作前,建议备份重要数据以免意外发生数据丢失。
确保操作前完全了解步骤,避免造成更大的错误或系统不稳定。
考虑联系技术支持寻求专业帮助,特别是当问题复杂或难以自行解决时。
电脑网络驱动丢失是一个常见但又困扰诸多用户的问题,通过上述方法,大多数关于网络驱动的问题都能得到有效解决,遇到此类问题时,应先从基础做起,逐步排查并尝试不同的解决方案,保持系统和驱动的及时更新也是预防此类问题发生的有效措施。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22