MySQL数据库兼容性,如何确保跨版本数据无缝对接?

MySQL数据库兼容性
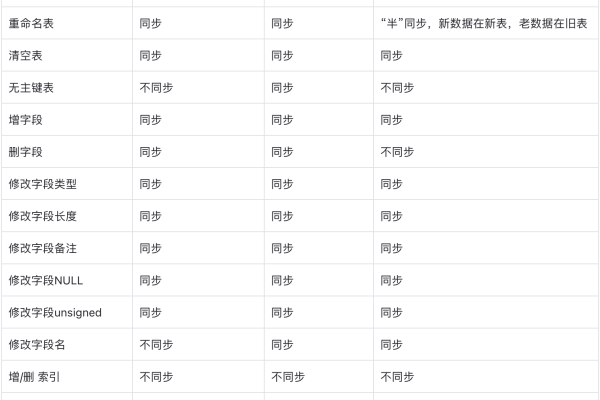
MySQL作为一种广泛使用的开源关系型数据库管理系统(RDBMS),其兼容性在跨平台和跨系统的数据交互中扮演着至关重要的角色,兼容性主要涉及不同数据库系统之间在SQL语法、数据类型、函数以及存储过程等方面的互操作性和适应性。
1. SQL语法差异
不同数据库系统之间的SQL语法存在显著差异,MySQL使用LIMIT子句进行分页查询,而SQL Server则使用TOP关键字,字符串连接在MySQL中使用CONCAT()函数,而在SQL Server中则直接使用加号(+),为了处理这些差异,开发人员可以使用条件语句和数据库抽象层(如ORM框架)来编写兼容不同数据库的SQL语句。
2. 数据类型差异
数据类型的定义和支持在不同数据库系统中也有所不同,MySQL支持ENUM和SET类型,而SQL Server则不支持,同一种数据类型在不同系统中可能会有不同的实现方式和限制,在进行数据迁移或集成时,需要进行数据类型的转换和映射。
3. 函数和存储过程的差异
MySQL和SQL Server在函数和存储过程的支持上也有所不同,MySQL中的存储过程语法与SQL Server存在差异,开发人员需要根据目标数据库的要求进行调整,MySQL对用户定义函数(UDF)的支持相对有限,而SQL Server则提供了更强大的功能。
4. 提高MySQL兼容性的方法
为了提高MySQL的兼容性,可以采取以下几种方法:
使用标准SQL语法:尽量使用标准的SQL语法,避免使用特定于某个数据库系统的扩展功能。
数据类型转换:在数据迁移过程中,使用数据类型转换函数将源数据库的数据类型转换为目标数据库的对应类型。
执行兼容性测试:在数据库迁移或集成之前,进行全面的兼容性测试,以发现并解决潜在的问题。
使用数据库迁移工具:利用专门的数据库迁移工具,可以简化数据迁移和兼容性处理的过程。
5. MySQL与其他数据库系统的兼容性对比
MySQL与多种数据库系统之间存在一定的兼容性,但也存在一些差异,MySQL与PostgreSQL在数据类型和SQL语法方面有较好的兼容性,但在存储过程和触发器方面则需要进行适当的调整,与Oracle相比,MySQL在PL/SQL语法和数据类型方面存在较大差异,需要进行更多的转换工作。
6. 常见问题解答
Q1: 如何确保数据类型的兼容性?
A1: 确保数据类型的兼容性可以通过使用数据类型转换函数或脚本进行转换,并在迁移前进行充分的测试。
Q2: 如何处理不同数据库系统的查询差异?
A2: 可以通过编写针对不同数据库系统的特定查询语句,或者使用ORM工具来处理查询差异。
Q3: 为什么需要进行兼容性测试?
A3: 兼容性测试可以帮助发现不同数据库系统之间的潜在问题,确保系统在迁移或集成后能够正常运行。
Q4: 如何降低数据库迁移成本?
A4: 通过充分规划和准备、使用自动化工具、执行兼容性测试等方法,可以有效降低数据库迁移的成本。
MySQL数据库的兼容性是一个复杂但至关重要的问题,通过了解不同数据库系统之间的差异,采取相应的措施,可以提高MySQL的兼容性,确保系统在不同数据库系统之间的顺利交互和迁移。
小伙伴们,上文介绍了“mysql数据库的_MySQL数据库兼容性”的内容,你了解清楚吗?希望对你有所帮助,任何问题可以给我留言,让我们下期再见吧。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11