如何有效实施快速迭代开发以加速产品上市时间?

快速迭代开发是当代软件开发领域的一种灵捷、高效的方法,旨在以最快的速度交付价值并持续改进产品,小编将}
{概述}={详细探讨快速迭代开发的各个方面:
1、核心原则和优势
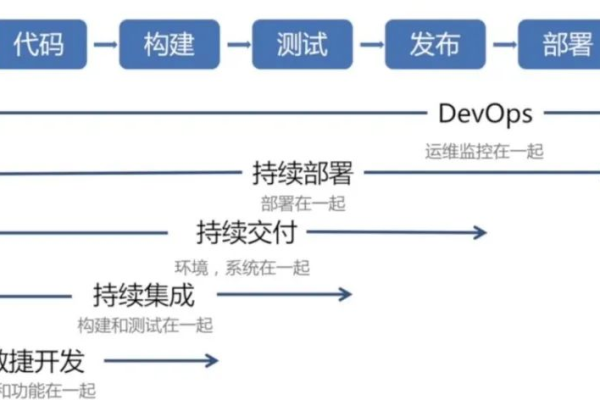
快速交付与反馈:快速迭代开发把开发过程分为多个快速的迭代周期,每个周期都是一个微型的项目管理周期,包括需求分析、设计、编码、测试和发布等阶段,这种方式使团队能够快速生成可用的软件版本,从而获得用户的早期反馈,并据此进行下一步的优化。
灵活性与风险管理:快速迭代开发允许开发团队根据用户反馈和市场变化灵活调整开发计划,同时在开发初期通过短迭代发现潜在的风险和问题,以便及早应对,这种方法有效减少了项目后期大幅修改的风险和成本。
2、主要框架和工具
Scrum与Kanban:Scrum和Kanban是两种流行的敏捷开发框架,均适用于快速迭代开发,Scrum 注重于团队协作和角色分工,规定了每个迭代周期(Sprint)的目标和任务计划,而Kanban则强调持续交付与流动效率,使用看板来管理任务的流动状态。
持续集成和部署:在迭代开发中,每次迭代结束时都进行集成和部分部署,这有助于减少项目尾声大规模集成的返工风险,持续集成(CI)和持续部署(CD)的工具如Jenkins、GitLab CI/CD 等,可以自动化这一过程,确保软件质量并加快交付速度。
3、挑战与注意事项
学习成本与管理复杂性:虽然迭代方法具有明显的优势,但也带来较高的学习成本和管理难度,团队成员需要深入理解敏捷思想和迭代开发的细节,项目经理也需具备良好的组织和协调能力来管理复杂的迭代流程。
目标明确与早示风险:成功的迭代开发需要清晰的项目目标和用户需求,不明确的目标会导致迭代失去方向,而忽视早期的迭代反馈则可能错过修复重大问题的机会。
4、案例分析与应用
Netflix的持续改进:Netflix 的流媒体服务是通过快速迭代开发不断优化用户体验的典型例子,他们通过不断推出新功能并进行A/B测试,基于用户反馈进行优化,持续提升用户满意度和留存率。
Spotify的敏捷实践:音乐流媒体公司Spotify以其独特的“部落”结构和敏捷开发团队而闻名,通过短周期的迭代快速响应市场变化,并定期发布新功能和改进,保持产品竞争力。
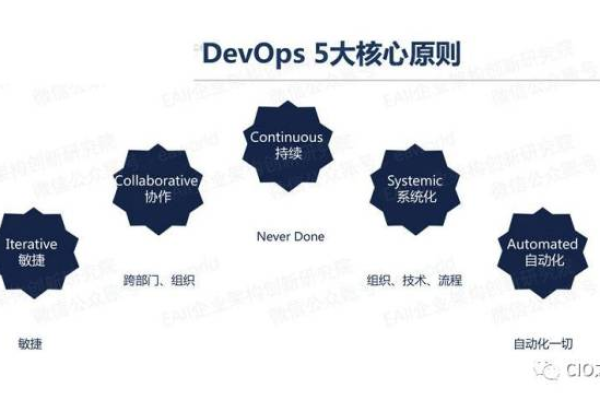
快速迭代开发作为一种现代软件开发方法,其最大的优点在于快速响应和适应变化的能力,以及在整个开发过程中持续提供价值,要充分发挥其潜力,团队需要深入理解敏捷开发的核心原则,采用合适的框架和工具,并克服由此带来的挑战,通过实际案例的分析,可以看到快速迭代开发不仅适用于初创公司,也能被大型企业成功应用,关键在于理解其精髓并适应特定项目的需求。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22