如何实现MySQL数据库的自动同步和镜像功能?

MySQL数据库的自动同步功能,特别是主从复制和镜像,是确保数据一致性和高可用性的重要机制,以下是对MySQL数据库自动同步功能的详细解析:
基本概念
1、主从复制:
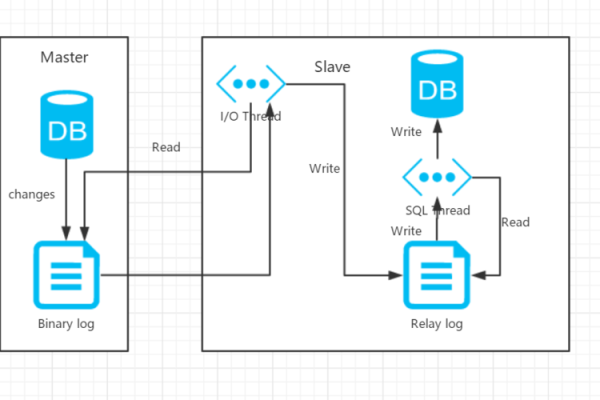
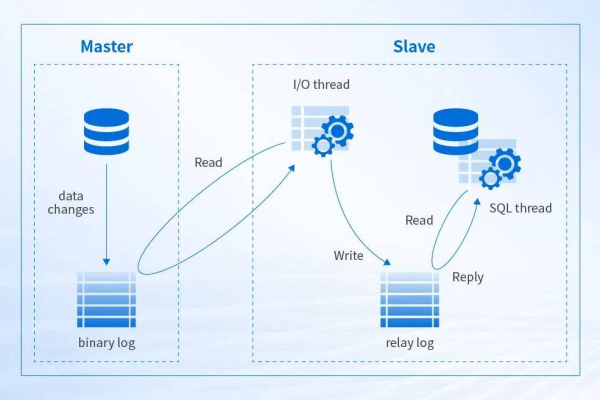
主从复制允许一个MySQL服务器(称为“主服务器”或“Master”)的数据自动复制到一个或多个MySQL服务器(称为“从服务器”或“Slave”)。
主服务器上的任何数据更改都将自动反映在从服务器上。
2、自动镜像:
自动镜像通常指的是通过某种机制实时地将数据库中的数据复制到另一个数据库中,以保持两个数据库数据的一致性。
在MySQL中,这可以通过配置主从复制来实现。
实现步骤
1、配置主从复制:
在主服务器上启用二进制日志(binlog)并创建一个用于复制的用户,授予该用户REPLICATION SLAVE权限。
在主服务器上查看二进制日志文件的状态信息,包括文件名和位置。
在从服务器上配置与主服务器的连接信息,包括主服务器的IP地址、用户名、密码以及二进制日志文件名和位置。
在从服务器上启动复制进程,使其连接到主服务器并开始同步数据。
2、设置自动同步:
确保主从服务器之间的网络连接稳定且延迟低。
根据业务需求调整复制策略,如全量复制、增量复制等。
监控复制状态和性能,及时处理可能出现的问题。
注意事项
1、安全性:
在配置主从复制时,务必注意安全性问题,如使用强密码、限制访问权限等。
避免将内部敏感数据暴露给外部未经授权的访问者。
2、性能影响:
主从复制会占用一定的系统资源和网络带宽,因此需要根据实际情况调整复制策略和参数。
在高负载情况下,可能需要优化复制性能或采用其他同步机制。
3、故障处理:
当主从复制出现故障时,应及时检查错误日志并采取相应措施进行修复。
在必要时,可以考虑重新同步数据或切换到备用方案以确保数据一致性。
应用场景
1、数据备份:
利用主从复制实现数据的实时备份,提高数据的安全性和可靠性。
2、读写分离:
将写操作集中在主服务器上执行,而读操作则分散到多个从服务器上执行,从而减轻主服务器的负载并提高系统的响应速度。
3、负载均衡:
通过将请求分发到不同的服务器上执行来平衡负载并提高整体性能。
MySQL数据库的自动同步功能通过主从复制机制实现数据的实时备份和一致性维护,在配置和使用过程中需要注意安全性、性能影响以及故障处理等问题,通过合理的规划和配置可以充分发挥其优势并满足不同应用场景下的需求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/142122.html
相关文章
-
如何实现MySQL数据库的镜像功能?
-
如何实现MySQL数据库的每日自动同步?
-
以下几个疑问句标题可供选择,,如何查看 RDS for MySQL 数据库死锁日志及 MySQL 表格字段相关问题解析,RDS for MySQL 死锁日志怎么查看?与 MySQL 表格字段操作探讨,怎样查看 RDS for MySQL 数据库的死锁日志?关于 MySQL 表格字段的思考,RDS for MySQL 数据库死锁日志查看方法与 MySQL 表格字段研究,如何查看 RDS for MySQL 数据库死锁日志?对 MySQL 表格字段的分析
-
如何实现MySQL数据库之间的实时数据同步和迁移?
-
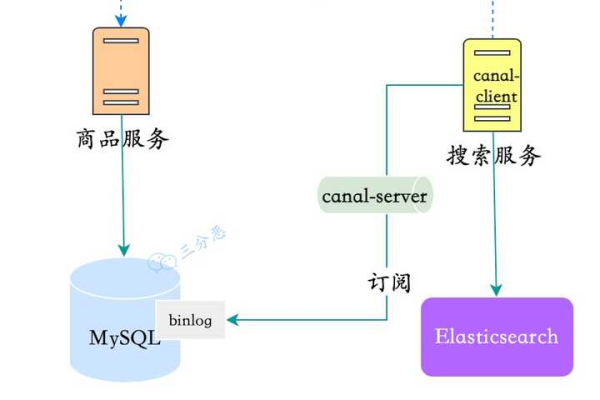
如何实现MySQL大数据同步,将数据从一MySQL数据库同步到另一MySQL数据库?
-
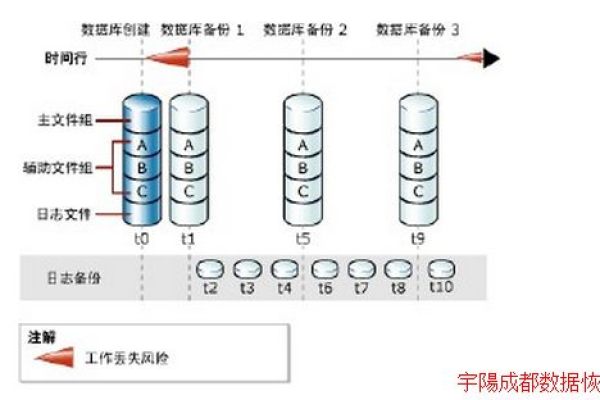
如何实现MySQL数据库的自动备份功能以及通过函数高效访问MySQL数据库?
-
如何实现MySQL数据库的自动建立与更新,并设置自动更新告警名称的功能?
-
如何实现MySQL数据库中ID的自动生成以及APP Code的自动创建?


