租虚拟主机的费用是多少?

1、价格影响因素
配置与规格:虚拟主机的价格主要取决于其配置,包括存储空间、带宽、流量和操作系统等,存储空间越大、带宽越高,价格也会相应增加,一个小型服务器(适用于10人,租用30天)的费用大约为3000绿宝石,而中型服务器(适用于20人,租用30天)的费用则为6000绿宝石。
服务类型与地域:不同服务商提供的服务类型和机房位置也会影响价格,国内虚拟主机通常按照网站空间、流量、带宽等因素定价,而双线机房的成本要比单线线路机房高,香港虚拟主机由于免备案且访问速度快,价格相对较高。
租期与优惠:长期租用通常比短期租用更具成本效益,租用180天的周期对于日常使用更具成本效益,而租用365天则更为划算,一些服务商会提供折扣和优惠活动,如两年八折、五年七折等。
附加服务:备份、域名等附加服务也会影响总费用,在选择虚拟主机时,需要考虑这些可能增加费用的服务。
2、常见价格范围
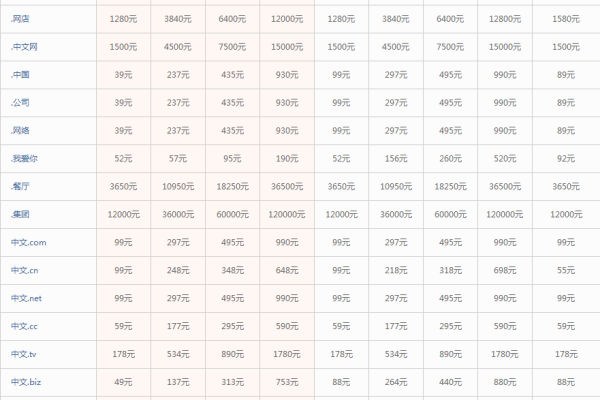
共享型虚拟主机:一般在100-1000元/年不等,适合中小型网站和个人用户。
VPS服务器:价格在500-5000元/年不等,根据CPU、内存、硬盘容量、网络带宽等配置不同而有所区别。
云服务器:价格在2000-1万元/年不等,适用于需要更高性能和稳定性的用户。
独立服务器:价格一般在1万元以上/年,适合大型企业和高流量网站。
3、选择建议
需求分析:根据自身需求选择合适的配置和服务商,如果需要高性能和稳定性,可以选择专业的虚拟主机租用服务商。
比较价格:在多家服务商之间进行比较,选择性价比高的选项。
考虑附加服务:了解是否有备份、域名等附加服务,并评估其费用。
关注优惠:利用服务商提供的折扣和优惠活动,降低租用成本。
租虚拟主机的价格因多种因素而异,包括配置、服务类型、地域、租期和附加服务等,在选择虚拟主机时,应根据自身需求和预算进行综合考虑,并在多家服务商之间进行比较,以选择最适合自己的方案,也要关注服务商的专业程度和服务质量,确保虚拟主机的稳定性和安全性。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22