CDN加速对网站性能的影响究竟有多大?

CDN加速效果明显,能显著提高网站访问速度和稳定性。
CDN加速的效果是明显的。
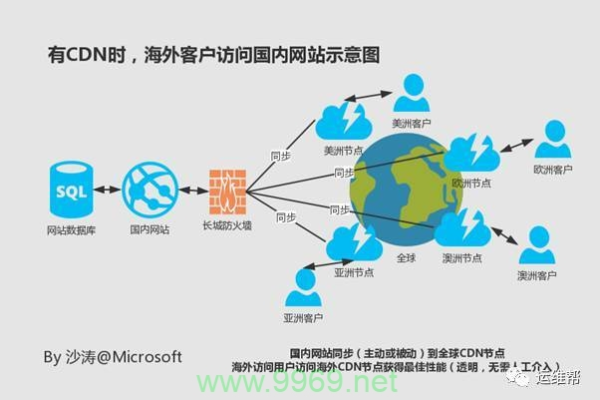
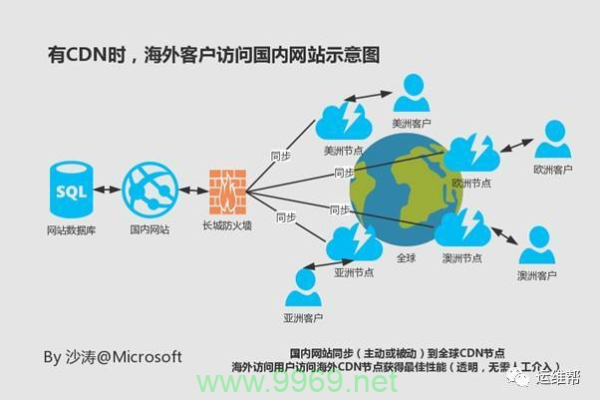
CDN加速通过在多个地理位置分布的服务器上缓存网站内容,使用户能够从最近的服务器获取数据,从而显著减少数据传输时间和延迟,未使用CDN时,一个位于美国的用户访问一个在中国托管的网站可能会经历较高的延迟;而使用CDN后,该用户的请求会被导向离他最近的CDN节点,从而加快加载速度。
CDN加速可以在以下几个方面产生明显效果:
1、提升用户体验:通过减少页面加载时间,降低跳出率,提高用户满意度和互动性。
2、优化搜索引擎排名:搜索引擎如Google将网站速度作为排名因素之一,使用CDN可以间接提升搜索结果中的排名。
3、提高转化率和销售量:快速响应的网站能更好地保持用户的注意力,从而提高转化率和销售额。
4、增强网站稳定性和安全性:CDN的分布式架构有助于分散攻击流量,提高网站的抵抗DDoS攻击的能力。
CDN加速不仅能够显著提升网站的加载速度和性能,还能间接带来其他商业价值,如改善用户体验、提高搜索引擎排名和增强网站的安全性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/142039.html