开源证券交易软件的可靠性如何?

开源证券交易软件_开源软件声明
开源证券交易软件是一种基于最新科技开发的金融工具,旨在为投资者提供一站式的金融服务平台,该软件不仅包括行情查看、证券交易等基础功能,还融入了多种增值服务,如数据分析、投资策略建议等,大大提升了投资者的交易体验和操作便利性。
开源证券交易软件提供了全面的市场数据和实时分析工具,神奇九转”指标,这一工具可以帮助投资者识别市场趋势的转变,从而作出更加科学的投资决策,软件支持一键打新功能,自动提醒并执行新股申购,极大地简化了操作流程,新增的主力增仓、资金流向等数据服务,使得投资者能够实时掌握市场动态,更好地规划自己的投资策略。
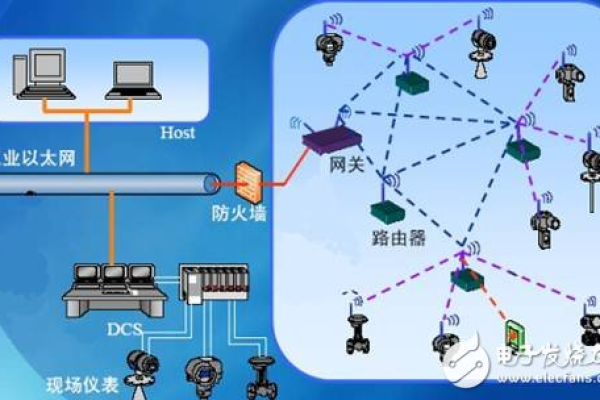
在技术架构方面,开源证券交易软件采用了类似LMAX交易所的Disruptor框架,这一高效的内存框架极大地提高了数据处理速度和交易撮合的效率,通过使用Hazelcast/Ignite进行分布式内存存取管理,软件能够在高并发的交易环境中稳定运行,保证了交易的高效和稳定。
随着“十四五”规划中对开源技术的支持以及多部门联合发布的金融业开源技术应用意见,开源证券交易软件的开发与应用得到了政策面的大力支持,这为开源证券软件的技术更新与服务优化提供了政策保障,使其能够持续推进技术创新和服务升级。
对于使用者而言,了解软件的UI界面、运行环境、版本信息是基本而必要的,根据介绍,开源证券尊享版软件适用于Windows 7及以上系统,具备直观的用户界面和便捷的操作特点,这为用户提供了良好的视觉体验和交互便利性。
开源软件的蓬勃发展背后,既有广阔的机遇也伴随着不少风险,对于金融机构而言,制定严格的开源软件管理政策和使用指南是保证系统安全和数据保密的关键,开源证券在软件开发和使用中遵循清晰的审批、获取流程,确保每一份代码的安全可靠。
开源证券交易软件以其强大的功能、高效的性能和用户友好的设计,正成为越来越多投资者的首选交易平台,随着技术的不断进步和政策的进一步支持,开源证券交易软件会持续刷新证券交易的市场标准,为用户提供更加专业和便捷的服务。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11