如何在Linux系统中进行用户分组操作?

在Linux操作系统中,用户分组是一个重要的概念,它有助于系统管理员更好地管理和控制用户权限,通过将用户分配到不同的组,可以实现对资源的更细粒度的访问控制,本文将详细介绍Linux用户分组的概念、操作以及常见问题解答。
一、Linux用户分组
在Linux系统中,每个用户都属于一个或多个用户组,用户组的主要作用是对一组用户进行统一管理,便于赋予这些用户相同的权限,一个项目团队的所有成员可以被添加到同一个用户组,以便他们共享对某些文件和目录的访问权限。
1. 用户组的类型
Linux中的用户组分为以下几种类型:
主组(Primary Group):每个用户都有一个主组,用户创建时会自动加入这个组,主组通常与用户的用户名相同。
附加组(Supplementary Groups):用户可以属于多个附加组,这些组提供了额外的权限。
系统组(System Groups):这些组通常用于系统进程和服务,而不是普通用户,它们的组ID通常小于1000。
自定义组(Custom Groups):由系统管理员根据需要创建的用户组。
二、用户分组的操作
1. 查看当前用户所属的组
要查看当前用户所属的所有组,可以使用groups命令:
groups [username]
如果不指定用户名,默认显示当前用户的组信息。
2. 创建新用户组
使用groupadd命令可以创建一个新的用户组:
sudo groupadd [groupname]
创建一个名为developers的组:
sudo groupadd developers
3. 删除用户组
使用groupdel命令可以删除一个用户组:
sudo groupdel [groupname]
注意,只有当该组没有任何成员时才能删除。
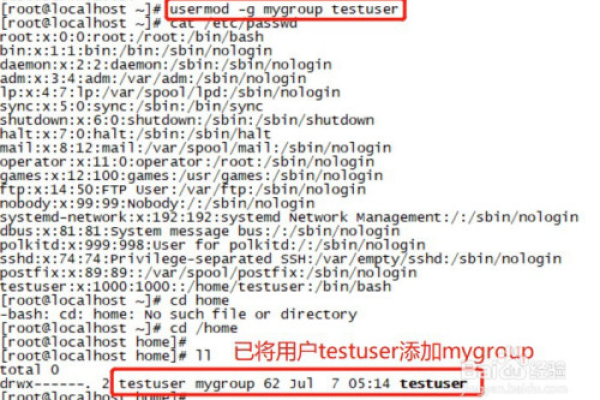
4. 将用户添加到用户组
使用usermod命令可以将用户添加到某个组:
sudo usermod -aG [groupname] [username]
将用户john添加到developers组:
sudo usermod -aG developers john
5. 从用户组中移除用户
同样使用usermod命令可以从用户组中移除用户:
sudo usermod -G [new_groups] [username]
将用户john从developers组中移除:
sudo usermod -G developers,!john john
6. 修改用户组名
使用groupmod命令可以修改用户组的名称:
sudo groupmod -n [new_groupname] [old_groupname]
将developers组重命名为devs:
sudo groupmod -n devs developers
三、用户分组的权限管理
1. 文件和目录的权限
在Linux中,每个文件和目录都属于一个所有者和一个组,通过设置适当的权限,可以控制不同用户和组对这些文件和目录的访问,设置一个文件的权限为rw-r--r,表示所有者具有读写权限,组成员和其他用户只具有读权限。
2. 特殊权限位
除了标准的读、写、执行权限外,Linux还提供了一些特殊权限位,如SUID(Set User ID)、SGID(Set Group ID)和Sticky Bit,这些权限位可以进一步增强用户组的管理能力。
四、常见问题解答(FAQs)
问题1:如何更改文件的所属组?
答:使用chgrp命令可以更改文件的所属组,将文件file.txt的所属组更改为developers:
sudo chgrp developers file.txt
问题2:如何同时更改文件的所有者和所属组?
答:使用chown命令可以同时更改文件的所有者和所属组,将文件file.txt的所有者更改为john,所属组更改为developers:
sudo chown john:developers file.txt
Linux用户分组是系统管理的重要组成部分,通过合理地使用用户分组,可以有效地控制用户权限,提高系统的安全性和管理效率,希望本文的介绍能够帮助读者更好地理解和使用Linux用户分组功能。
各位小伙伴们,我刚刚为大家分享了有关“linux 用户分组”的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11