国内信创服务器市场排名情况如何?

在中国信息技术产业中,信创(信息创新)服务器是推动国内技术自主可控和信息安全的关键部分,随着国家对于信息化和软件服务业的大力扶持,信创服务器行业迎来了快速发展期,国内众多企业在服务器领域取得了显著的成绩,不断提升自主研发能力,涌现出了一批具有国际竞争力的信创服务器品牌,具体如下:
1、综合实力与市场竞争力
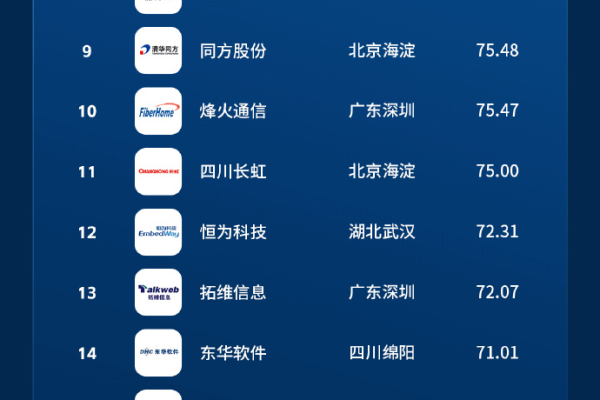
企业规模和市场份额:在国内信创服务器市场中,企业的综合实力往往与其规模和市场份额密切相关,据iiMedia Ranking发布的《2023年中国信创服务器企业TOP15》榜单显示,排名靠前的企业通常具有较强的研发实力、成熟的生产线以及广泛的销售网络。
技术研发和创新能力:技术创新是信创服务器企业的核心竞争力之一,通过不断的技术研发,这些企业能够提供更为先进的产品以满足市场需求,艾媒金榜的数据评价模型提到,研发性和创新性是评价企业排名的重要指标。
2、产业链合作与生态系统
上下游产业链整合:优秀的信创服务器企业不仅在产品技术上有所突破,还注重与上下游产业链的合作,通过整合资源,优化供应链管理,这些企业能够更好地控制成本,提高运营效率。
生态系统建设:构建良好的产业生态系统也是提升企业竞争力的关键,包括与软硬件开发商、服务提供商等合作伙伴建立紧密的合作关系,共同推动信创产品的发展和优化。
3、品牌影响力与市场传播
品牌认知度:在国内市场,品牌的影响力对消费者的购买决策有着直接的影响,拥有良好品牌形象的信创服务器企业更容易获得市场的认可和推广。
网络传播与社会评价:随着社交媒体和在线平台的发展,网络传播成为衡量企业品牌力的另一重要因素,社会评价好的企业往往能够在潜在客户中形成良好的口碑效应。
4、政策支持与行业地位
国家政策倾斜:由于信创服务器涉及国家安全及信息化建设的关键领域,国家相关政策的支持对企业的发展至关重要,政策倾斜可以为企业带来更多的资源和市场机会。
行业地位和领导力:在专业排行榜中的高位次也反映了企业在信创服务器行业中的地位和领导力,排名靠前的企业常常被视为行业的标杆,引领技术和市场趋势。
5、客户满意度与服务品质
客户反馈与满意度:最终用户的使用体验和满意度是评价信创服务器企业的重要标准,高客户满意度意味着产品在实际操作中的优越表现和可靠性。
售后服务体系:完善的售后服务体系能够确保客户在使用产品过程中得到及时有效的技术支援,这也是企业服务质量和客户忠诚度的重要体现。
在了解以上内容后,以下还有几点需要注意:
关注政府及相关行业协会发布的最新政策和市场报告,以获取详尽的行业分析与企业排名信息。
在选择信创服务器产品时,考虑厂商的综合实力、技术支持能力及用户评价,以确保选择到高性价比的产品。
对于有意向进入该领域的企业或个人,可以通过行业论坛、研讨会等方式深入了解市场动态和企业发展趋势。
通过以上详细解析,人们可以看出国内信创服务器行业的竞争格局以及各企业在市场中的表现,这不仅为消费者提供了选择参考,同时也为业界人士提供了行业发展的宏观视角,在此基础上,小编将探讨两个与国内信创服务器排名相关的常见问题,并提供相应的解答。
相关问题与解答
Q1: 如何验证信创服务器企业的实力和市场信誉?
A1: 可以通过查看企业在各类信创服务器排行榜中的排名情况,如《2023年中国信创服务器企业TOP15》等权威榜单,关注企业的融资情况、技术创新案例、客户反馈及媒体报道等也是重要的验证手段。
Q2: 未来国内信创服务器行业的发展趋势如何?
A2: 预计未来国内信创服务器行业将继续向高端化、智能化方向发展,随着国家政策的持续支持和市场需求的增加,行业内的竞争将更加激烈,技术创新和产业链协作将成为企业发展的关键,企业间的合作与并购活动可能会更加频繁,以实现资源的优化配置和整体竞争力的提升。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11