方舟游戏今日新增的服务器具有哪些特色和功能?

今天是2024年8月31号,星期六,方舟”新开的服务器,暂时无法提供具体的名称和详细信息,主要是因为搜索结果中没有直接提及今日新开服务器的确切消息,可以提供一些相关的背景信息和可能的线索,以帮助解答这个问题:
1、游戏审批与新服可能性
2024年8月国产游戏版号:国家新闻出版署刚刚下发了2024年8月国产游戏版号,共117款国产网络游戏过审,其中包括《明日方舟:终末地》等游戏,这暗示着可能会有新的服务器随着新版号的发布而开启。
新服开启活动:对于新服的开启,通常会有特别的活动来吸引和奖励早期加入的玩家,某些活动可能会向特定时间前注册并创建角色的玩家发放包含各种游戏内活动的活动邮件。

2、服务器开设频率与模式
定期开设新服:某些游戏会定期开设新服务器来平衡玩家数量,保持游戏生态的活力,有的游戏设定每三天开设一个新服,从初始地图开始,逐步扩展游戏内容。
3、玩家对新服务器的期待

社区互动与讨论:在游戏社区中,玩家经常会对即将开设的新服务器进行讨论和预测,这可以作为了解新服务器动态的一个窗口。
新旧玩家的需求:新服的开设往往吸引了不同层次的玩家,无论是新手还是老玩家都可能对新服务器有着不同的期待和需求。
4、游戏版本与平台

多平台运营:根据搜索结果,有些游戏不仅覆盖移动端,还可能涉及客户端和PS5平台,这表示游戏的服务器可能需要同时考虑多个平台的兼容性和联动。
虽然无法直接回答今日“方舟”所开新服的具体信息,但通过相关背景信息的梳理,可以合理推测,随着新版号的发布和游戏版本的更新,近期内可能会有关“方舟”新服务器的开设,建议关注官方公告或参与游戏社区的讨论,以获取最新和最准确的开服信息。
相关文章
-

吃鸡3件新衣服是什么服务器 这句话似乎在询问关于某款游戏(可能是绝地求生或类似的吃鸡游戏)中新增的三件服装与特定服务器之间的关联。为了生成一个原创的疑问句标题,我们可以稍微调整一下语句,以增加吸引力和信息量,,揭秘最新更新,绝地求生新增三款服装专属哪个服务器?,不仅提出了问题,还明确了游戏的名称,并且暗示了这些新服装可能仅在某些服务器上可用,从而吸引玩家点击了解详情。
-

通达国际平台的MT4服务器具有哪些特点和功能?
-

黑曼君服务器具有哪些特性和功能?
-
云服务器具有哪些特性和功能
-

云计算有哪些特征(云计算都有哪些特征)(云计算具有哪些特点?)
-

网易我的世界首个服务器具有哪些特色?
-

三门峡御海提供的服务器服务有哪些特色和优势?
-
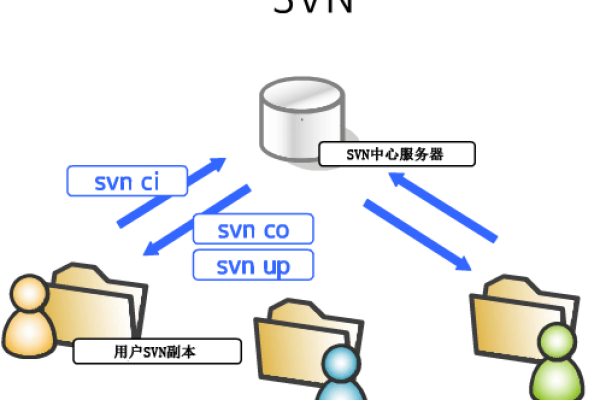
公司内部使用的SVN服务器具体承担哪些角色和功能?








