上一篇
decimal类型_Hudi写入小精度Decimal数据失败
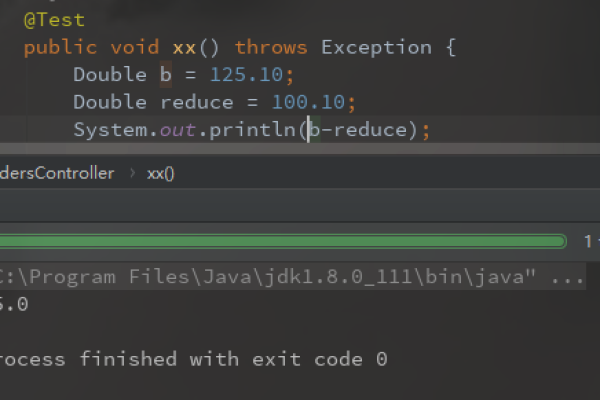
在使用Hudi处理小精度Decimal数据时,可能会遇到写入失败的问题。这可能是由于decimal类型的精度设置不正确或与Hudi的数据类型不兼容导致的。建议检查并调整decimal类型的精度设置,确保其与Hudi的要求相匹配。
在面对Hudi写入小精度Decimal数据时,可能会遇到写入失败的问题,这主要是由于Spark和Hudi在处理Decimal类型数据时存在一些不兼容的情况所导致的。
需要理解问题的根源,当数据包含Decimal类型时,使用Spark的parquet写入类进行BULK_INSET操作是没有问题的,当执行UPSERT操作时,Hudi会使用Avro兼容的parquet文件写入类,这一机制与Spark的处理方式不兼容,这种不兼容主要体现在对Decimal数据类型的处理上,不同精度的Decimal类型在Spark和Hudi中的处理方式有所不同。
解决这个问题的一个有效方法是在数据导入Hudi之前,转换涉及的Decimal类型数据,可以将Decimal类型转换为字符串类型或其他Hudi可接受的数据类型,这需要对数据进行预处理,确保所有Decimal字段都符合Hudi的写入要求。
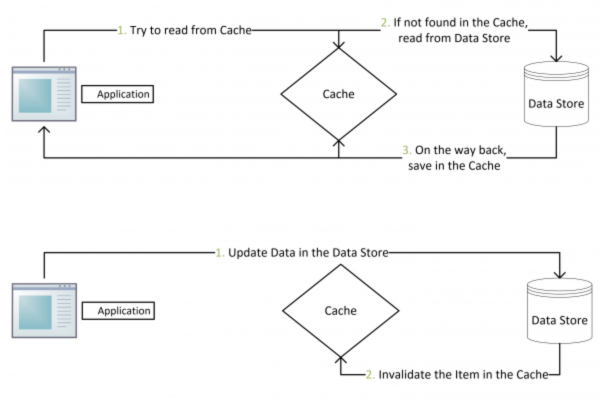
了解数据的摄取来源也是重要的一环,如果数据来自于Kafka或Tailbased FileSystem(例如HDFS),则可以使用DeltaStreamer来简化数据的摄取过程,DeltaStreamer提供了一个易于管理的解决方案,帮助用户将数据从各种源写入到Hudi中,用户也可以编写自定义代码,利用Spark数据源API从自定数据源获取数据,并使用Hudi数据源将这些数据写入到Hudi表中。
对于实际的配置示例,可以参考已有的示例配置,如从Kafka和DFS摄取数据的示例配置可见于hudiutilities/src/test/resources/deltastreamerconfig,这些示例提供了如何配置和运行DeltaStreamer以测试数据整合的指南。
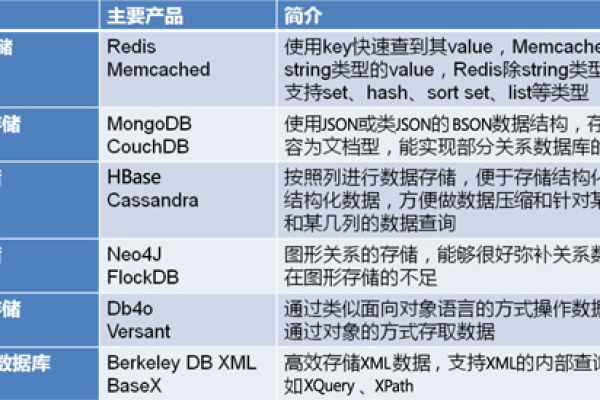
了解不同的Hudi表类型也对解决问题有所帮助,Hudi定义了两种表类型:写入时复制(CopyOnWrite, CoW)和读取时合并(MergeOnRead, MoR),这两种表类型在布局上有所不同,CoW没有日志文件,并且写入操作会导致commit操作而不是delta commit,对这两种表类型的深入了解可以帮助更好地设计数据存储方案。
如果在实际操作中仍遇到困难,可以考虑寻求专业的技术支持,或是参考更多先进的资源,如数据湖架构开发的进阶视频和资料,这些都提供了关于Hudi基础及应用进阶的详细解读。
解决Hudi写入小精度Decimal数据失败的问题主要涉及到数据类型的转换和合适的数据摄取方法的选择,通过适当的预处理和选择合适的工具和方法,可以有效地解决这一挑战。
FAQs
为什么在使用Hudi时会遇到Decimal数据类型写入失败的问题?
这是因为在执行UPSERT操作时,Hudi使用的是Avro兼容的parquet文件写入类,这与Spark的内部parquet文件写入类不兼容,这种不兼容主要表现在对Decimal数据类型的处理上。
如何解决Hudi无法写入Decimal类型数据的问题?
一个有效的解决方法是在数据导入Hudi之前,将涉及的Decimal类型数据转换成字符串类型或其他Hudi支持的数据类型,使用如DeltaStreamer这样的工具也可以简化数据摄取的过程,并减少此类问题的发生。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/131215.html