上一篇
大数据挖掘dt机器学习 _机器学习端到端场景
大数据挖掘结合机器学习技术,实现从数据预处理到模型部署的端到端场景。通过分析海量数据集,训练算法提取有价值信息,优化决策过程,并自动化实施解决方案,以提高效率和预测准确性。
在大数据时代,机器学习已经成为了数据分析、决策支持和智能系统不可或缺的技术之一,端到端的机器学习场景涵盖了从数据预处理到模型部署的全过程,确保了项目实施的高效性和准确性。

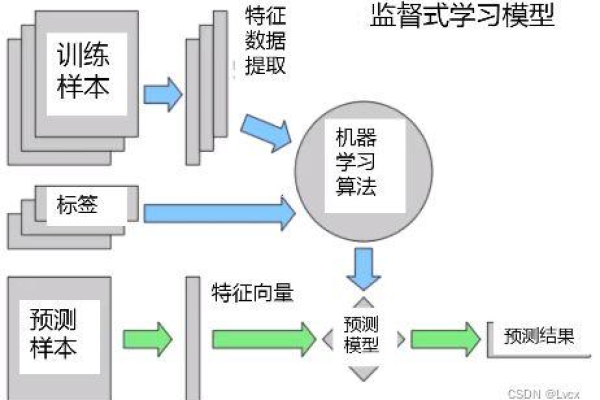
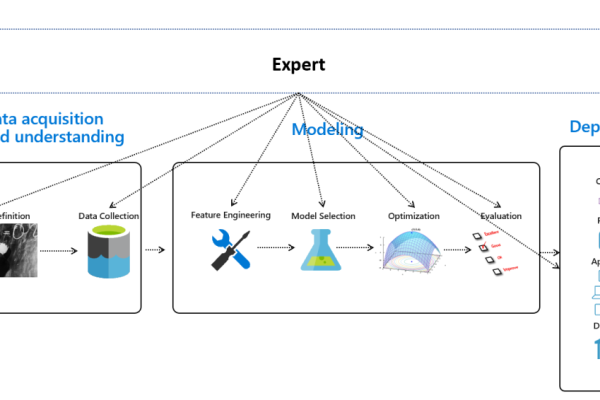
在大数据挖掘与机器学习中,端到端的场景主要涉及以下几个关键步骤:数据预处理、模型选择、模型训练、模型评估和模型部署,每一个步骤都是构建有效机器学习系统的重要组成部分。
数据预处理是机器学习项目的基础,这一阶段主要包括数据清洗、数据集成、数据转换和数据规约等任务,高质量的数据能够提高后续模型训练的效率和准确度,通过处理缺失值、异常值和标准化数据,可以提升数据的可用性。
选择合适的机器学习模型对于解决特定问题至关重要,根据问题的性质(如分类、回归或聚类),选择最合适的算法,对于分类问题,可以选择逻辑回归、支持向量机或神经网络等模型。
模型训练是使用已选模型和预处理的数据来调整模型参数的过程,这一阶段需要设定适当的超参数,如学习率、迭代次数等,这些参数直接影响模型的学习效果和泛化能力。
模型评估是通过测试数据集来评价模型性能的步骤,常见的评估指标包括准确率、召回率、F1分数等,这一步骤确保了模型在未知数据上的表现符合预期。
模型部署是将训练好的模型应用到实际环境中,进行预测或分类任务,在生产环境中,模型的部署需要考虑系统的可扩展性、稳定性和容错能力。
每个步骤都不可或缺,共同构成了端到端的机器学习应用场景,在实际应用中,各步骤之间可能存在反馈循环,即后一阶段的输出可能需要重新调整前一阶段的处理策略,这种动态调整保证了机器学习项目的适应性和持续优化。
FAQs
Q1: 如何选择合适的机器学习模型?
A1: 选择机器学习模型时,应考虑问题的类别(分类、回归或聚类)、数据的特性(大小、质量和特征数量)以及预期的性能(速度和准确度),还应考虑模型的可解释性和维护成本。
Q2: 如何处理机器学习中的过拟合问题?
A2: 过拟合可以通过增加数据量、使用正则化技术(如L1、L2正则化)、采用交叉验证以及引入模型早停等策略来处理,选择合适复杂度的模型也是防止过拟合的重要手段。
端到端的机器学习场景覆盖了从数据处理到模型部署的全过程,每一步都需要精心设计和执行以实现最佳性能,通过不断优化每个步骤,可以显著提升机器学习项目的效果。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/130246.html