域名服务器为何不适用于某些协议?

域名服务器不适用TCP协议。
域名系统(DNS)是互联网中极其关键的基础设施,其主要职能是将人类友好的域名翻译成机器可读的IP地址,这一过程通常涉及到多种网络协议,但并不是所有协议都适用于域名服务器的操作,将详细探讨域名服务器使用的通讯协议以及它们的具体应用场景:
1、DNS的通信协议
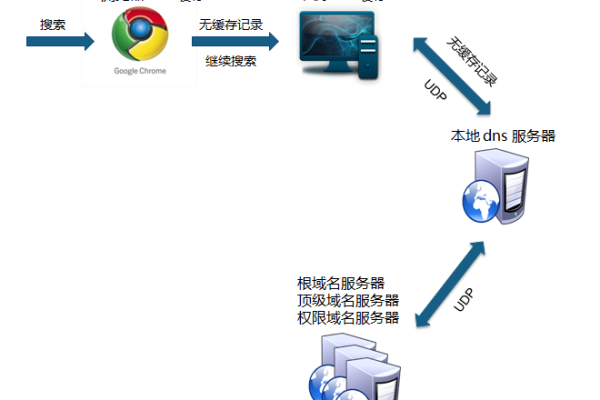
UDP协议的应用:在DNS的查询过程中,用户首先与本地DNS服务器进行交互,此时主要使用UDP协议,UDP是一个无连接的协议,它不保证数据包的传输和顺序,但由于其低开销特性,它非常适合于简单快速的查询响应,比如将域名解析为IP地址,大多数的DNS查询都可以通过UDP协议来完成,因为这类查询通常不会产生大量的数据。
TCP协议的特例:尽管DNS主要依赖UDP,但在一些特殊情况下,如区域传输(当辅助DNS服务器同步主DNS服务器的数据时),则必须使用TCP协议,TCP提供了可靠的数据传输服务,确保数据完整性和顺序,适用于大数据量传输的场景。
2、DNS的缓存机制
缓存的作用:当本地DNS服务器接收到查询请求后,会先在自身的缓存中查找是否有对应的IP地址,这种缓存机制大大加快了DNS解析的速度,提高了效率,若操作系统或应用程序频繁地请求同一域名,可以从缓存中直接获取结果,减少网络请求的次数。
缓存更新:若本地DNS服务器在缓存中未找到相应的记录,它将会向上游的根DNS服务器或其他DNS服务器发起请求,获取所需的IP地址信息,此过程可能涉及跨多个层级的查询,直至找到正确的记录,随后该记录会被存储在本地DNS服务器的缓存中以备后用。
3、DNS的查询流程
递归查询:当用户设备需要访问一个特定的域名时,它会向本地DNS服务器发送一个查询请求,如果本地DNS服务器没有所需的信息,它则会执行递归查询,即代替客户端向其他DNS服务器查询,直到获得答案或失败为止。
迭代查询:在递归查询过程中,本地DNS服务器可能会向根DNS服务器、顶级域DNS服务器等相关服务器发起迭代查询,每次查询都会根据参考答案逐步靠近存有目标数据的服务器,从而最终获取到完整的结果集。
4、DNS的服务器类型
主DNS服务器:每个域名至少有一个主DNS服务器,它维护着该域名的权威记录,任何关于该域名的更改首先会在主DNS服务器上进行。
辅助DNS服务器:为了提高域名解析的可用性和冗余性,一个域名可以有一个或多个辅助DNS服务器,这些服务器同步来自主DNS服务器的数据,并在主服务器不可用时提供解析服务。
5、通信协议的选择依据
响应数据量:UDP协议适用于数据量较小的DNS响应,当响应报文长度超过512字节时,UDP只能传输前512个字节,超出部分将被丢弃,这导致大区域传输时必须使用TCP协议。
可靠性需求:虽然UDP在正常情况下足够用于DNS解析,但对于需要确保数据完整性和顺序的场景,如区域传输,DNS会切换到TCP协议以保证数据的可靠传输。
域名服务器主要使用UDP协议进行日常的域名解析操作,只有在特定情况下,如大数据量的区域传输时才会使用TCP协议,了解DNS的工作机制及其对协议的选择,有助于人们更好地理解互联网的运行原理及优化网络配置,对于网络管理员而言,掌握这些知识是进行网络诊断和优化的基础,同时也有助于规划更加高效稳定的网络架构。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20