Een究竟是什么意思?

EEN是“异常教育需求”的缩写,用于描述需要特殊教育支持的学生。
“een”这个词汇,在不同语境下具有多种含义,以下是对“een”的详细解释:
1、网络用语或口语表达:在网络语境或日常口语中,“een”通常被用作一种情绪化的表达,类似于“嗯”或“嗯嗯”,用来表示对某件事情的认同或回应,这种用法往往带有一种轻松、非正式的氛围,有时甚至可以视为一种快捷的打字方式,以表示自己在倾听或者同意对方的观点,这样的使用场景下,它的具体含义需要根据对话内容来解读,也可能根据对话双方的关系和语境产生不同的含义。
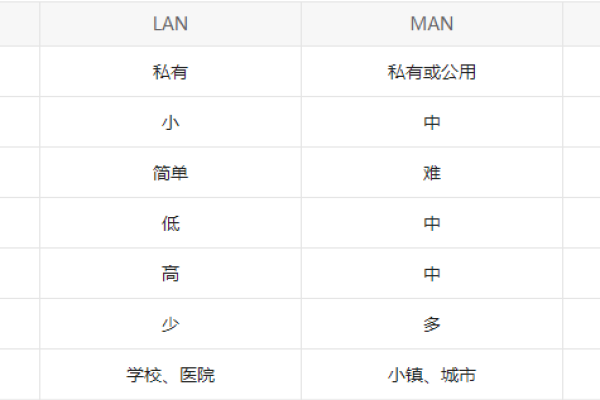
2、缩写形式:在科技领域,“EEN”有特定的专业含义,其全称为Enterprise Education Network(教育机构专用网络),作为教育机构专用网络的一种缩写,主要用于教育资源的共享和学术交流,在这种情境下,“EEN”代表了一个更为正式和专业化的概念,用于描述教育机构之间建立的网络连接和资源共享机制,这种网络通常涵盖了多个教育机构,包括学校、图书馆、科研机构等,旨在促进教育资源的互通和学术合作。“EEN”在这种情境下是一个专业术语的缩写形式。
3、其他含义:除了上述两种主要含义外,“een”还可能指代其他事物或概念,在某些特定领域或文化背景下,“een”可能具有特定的含义或用途,随着语言的发展和变化,“een”的含义也可能不断演变和丰富。
“een”是一个多义词,其含义需要根据上下文来判断,在使用“een”时,应结合具体语境进行解读,以确保准确理解其含义,也需要注意避免在不适当的场合使用该词汇,以免造成误解或混淆。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/126327.html