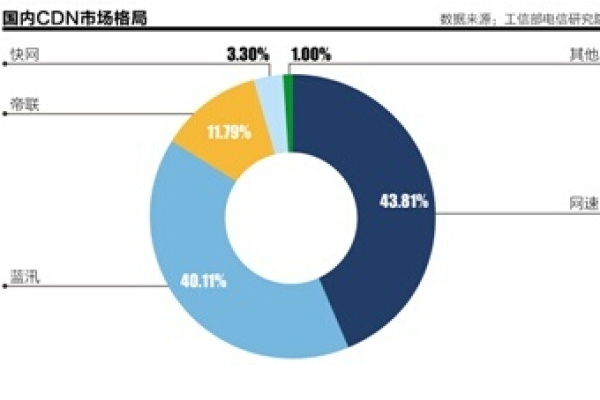
CDN年底洗牌,行业将迎来哪些变革与挑战?

随着互联网技术的飞速发展和全球数据流量的激增,内容分发网络(CDN)行业迎来了前所未有的发展机遇,伴随着机遇的是激烈的市场竞争和不断变化的行业格局,近年来,CDN行业经历了多轮洗牌,尤其是年底时段,各大厂商纷纷调整战略,以应对市场变化和挑战。
一、CDN行业现状与挑战
CDN作为互联网基础设施的重要组成部分,其主要功能是通过分布式的网络节点,将内容高效地分发给用户,从而提高访问速度和用户体验,随着云计算、大数据、物联网等技术的快速发展,CDN行业面临着新的技术要求和市场需求,随着5G、边缘计算等新技术的兴起,CDN行业也迎来了新的发展机遇。
市场竞争日益激烈,价格战频发,导致行业利润空间不断压缩,随着技术的不断进步和用户需求的多样化,CDN厂商需要不断创新和提升服务质量,以满足客户的个性化需求,这些挑战使得CDN行业面临着重新洗牌的局面。
二、年底洗牌的原因与影响
年底是CDN行业的一个重要时间节点,许多厂商会在这个时期进行战略调整和业务优化,随着年底的到来,各大厂商开始归纳过去一年的业务表现,评估市场份额和竞争力;他们也会为来年的市场布局做准备,包括调整价格策略、优化产品服务、拓展新市场等。
年底洗牌对CDN行业产生了深远的影响,它加剧了市场竞争的激烈程度,各大厂商为了争夺市场份额,纷纷采取降价、促销等手段吸引客户,导致行业整体利润水平下降,洗牌促使厂商不断提升自身的技术实力和服务质量,在激烈的市场竞争中,只有具备核心竞争力的企业才能脱颖而出,洗牌也推动了行业的创新和发展,为了应对市场变化和挑战,厂商需要不断创新产品和服务模式,以满足客户的多样化需求。
三、CDN行业未来趋势与展望
展望未来,CDN行业将继续保持快速发展的态势,随着5G、物联网等新技术的普及和应用,CDN的应用场景将进一步拓展,随着边缘计算、人工智能等技术的融合应用,CDN将迎来更加智能化和个性化的发展阶段。
在这个过程中,CDN厂商需要关注以下几个方面的趋势:一是加强技术创新和研发投入,提升产品的技术含量和附加值;二是优化客户服务体验,提供更加个性化和定制化的解决方案;三是拓展新兴市场和应用领域,寻找新的增长点;四是加强合作与共赢,与产业链上下游企业建立紧密的合作关系,共同推动行业的发展。
四、数据与案例分析
为了更好地了解CDN行业的年底洗牌现象及其影响,我们收集了一些相关的数据和案例进行分析,以下是部分数据的展示(由于数据来源和时间的限制,以下数据仅供参考):
| 年份 | CDN市场规模(亿元) | 同比增长率(%) | 主要厂商市场份额(%) |
| 2018 | 120 | 30 | A厂商30%,B厂商25%,C厂商20% |
| 2019 | 150 | 25 | A厂商32%,B厂商23%,C厂商18% |
| 2020 | 180 | 20 | A厂商35%,B厂商20%,C厂商15% |
从上表可以看出,CDN市场规模持续增长但增速有所放缓,同时主要厂商之间的市场份额也在发生变化竞争日益激烈。
以A厂商为例该厂商在2018年至2020年间通过不断的技术创新和市场拓展成功提升了市场份额,然而在年底洗牌的过程中该厂商也面临着来自其他竞争对手的挑战和压力,为了保持领先地位A厂商采取了多项措施包括加大研发投入、优化产品服务、拓展新兴市场等,这些措施使得A厂商在激烈的市场竞争中保持了较强的竞争力。
五、相关问答
问:CDN年底洗牌的主要原因是什么?
答:CDN年底洗牌的主要原因包括市场竞争日益激烈、价格战频发导致行业利润空间压缩;技术进步和用户需求多样化促使厂商不断创新和提升服务质量;以及厂商为来年市场布局做准备的战略调整等。
问:年底洗牌对CDN行业有哪些积极影响?
答:年底洗牌促使厂商不断提升自身的技术实力和服务质量;推动行业创新和发展;拓展新兴市场和应用领域;加强合作与共赢等,这些都有助于提升整个行业的竞争力和发展潜力。
问:面对年底洗牌CDN厂商应如何应对?
答:CDN厂商应加强技术创新和研发投入提升产品的技术含量和附加值;优化客户服务体验提供更加个性化和定制化的解决方案;拓展新兴市场和应用领域寻找新的增长点;加强合作与共赢与产业链上下游企业建立紧密的合作关系共同推动行业的发展,同时还需要密切关注市场动态和客户需求变化及时调整战略和业务模式以应对市场的挑战和机遇。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/126260.html