
上一篇
如何在MapReduce中导入新API到新的分组?
MapReduce新API允许开发者将API导入新的分组,简化了代码组织和管理。通过这种 分组机制,可以更高效地管理和调用相关功能,提高开发效率和代码可读性。
MapReduce 新API导入API到新分组

MapReduce API是Google Cloud Dataflow的一部分,它允许你使用简单的编程模型来处理大规模数据,以下是如何导入MapReduce API并创建一个新的分组的步骤:
1. 安装必要的库
你需要安装Google Cloud Dataflow库,你可以使用pip进行安装:
pip install apachebeam[gcp]
2. 导入必要的模块
在你的Python脚本中,导入必要的模块:
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions
3. 设置Pipeline选项
创建一个PipelineOptions对象,用于配置你的Dataflow管道,你可以指定项目ID、区域和GCP凭据文件路径等:
pipeline_options = PipelineOptions() pipeline_options.view_as(beam.options.pipeline_options.GoogleCloudOptions).project = 'yourprojectid' pipeline_options.view_as(beam.options.pipeline_options.GoogleCloudOptions).region = 'yourregion' pipeline_options.view_as(beam.options.pipeline_options.GoogleCloudOptions).job_name = 'yourjobname' pipeline_options.view_as(beam.options.pipeline_options.StandardOptions).runner = 'DataflowRunner' pipeline_options.view_as(beam.options.pipeline_options.StandardOptions).temp_location = 'gs://yourbucket/temp'
4. 创建管道
使用上面定义的pipeline_options创建一个管道:
with beam.Pipeline(options=pipeline_options) as p:
# Your pipeline logic goes here5. 定义数据处理逻辑
在管道内部,你可以定义你的数据处理逻辑,假设你有一个包含用户信息的数据集,你想要根据用户的国家对他们进行分组:
def group_by_country(element):
user, country = element
return (country, user)
with beam.Pipeline(options=pipeline_options) as p:
users = p | 'Read from BigQuery' >> beam.io.ReadFromBigQuery(query='SELECT name, country FROM users')
grouped_users = users | 'Group by Country' >> beam.Map(group_by_country) | 'Group By Key' >> beam.GroupByKey()在这个例子中,我们首先从BigQuery读取用户数据,然后使用group_by_country函数将每个用户与其国家关联起来,我们使用GroupByKey操作按国家对用户进行分组。
6. 运行管道
运行管道以执行你的数据处理任务:
if __name__ == '__main__':
result = p.run()
result.wait_until_finish()这样,你就成功地导入了MapReduce API并创建了一个新的分组。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/126131.html
相关文章

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
如何通过MapReduce REST API接口管理MapReduce作业?
如何使用Java MapReduce API来掌握MapReduce编程?
Mongo Java MapReduce: 如何利用Java API接口实现MapReduce功能?
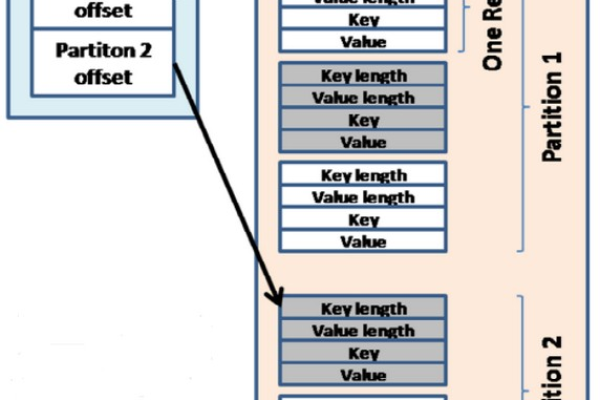
MapReduce Shuffle调优,如何优化MapReduce中的Shuffle过程?
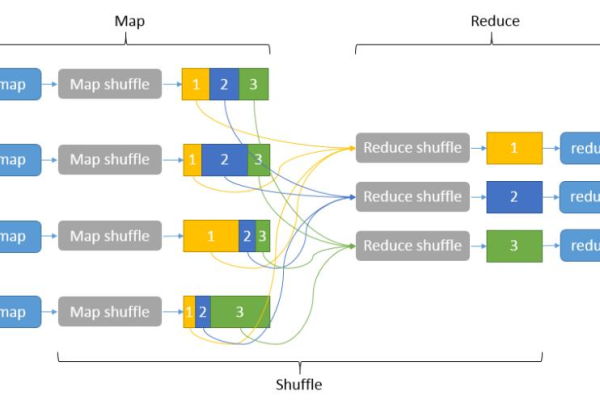
MRS MapReduce中MapReduce节点如何实现高效数据处理的优化策略?
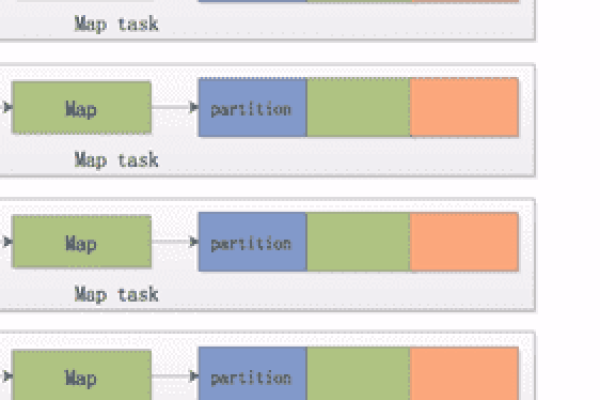
如何理解和使用MapReduce中的cmdenv_MapReduce命令?








