c 数据库连接不上

C 语言中数据库连接不上的详细解答
在C语言开发中,连接数据库是一个常见且重要的任务,有时会遇到无法连接到数据库的问题,本文将详细介绍可能导致这一问题的原因以及相应的解决方案。
一、常见问题及原因分析
1、驱动程序问题
原因:未安装或安装了错误的数据库驱动。
解决方案:确保已安装正确版本的数据库驱动程序,并配置好环境变量。
2、网络问题
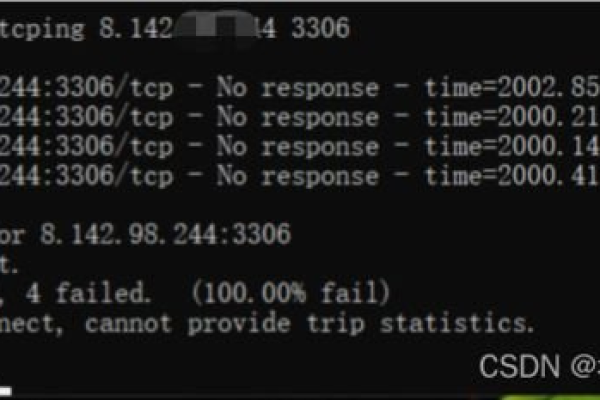
原因:数据库服务器不可达或网络不通。
解决方案:检查网络连接,确认能够ping通数据库服务器地址,必要时联系网络管理员。
3、认证失败
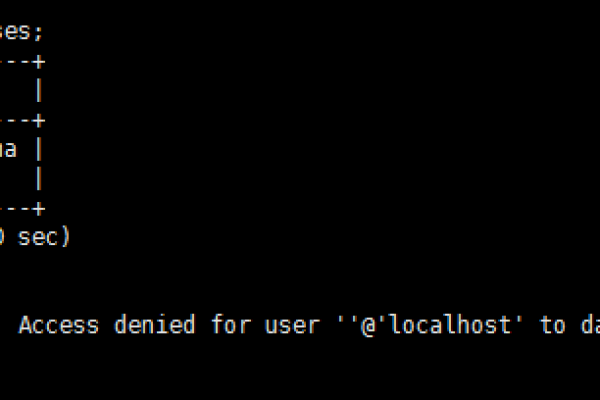
原因:用户名或密码错误,权限不足。
解决方案:核对数据库用户名和密码,确保具有足够的权限访问数据库。
4、数据库服务未启动
原因:数据库服务未运行或崩溃。
解决方案:检查数据库服务状态,必要时重启数据库服务。
5、SQL语法错误
原因:SQL查询语句有误。
解决方案:检查SQL语句,确保语法正确无误。
6、库文件缺失或路径不正确
原因:缺少必要的库文件或库文件路径配置错误。
解决方案:确认所有必需的库文件都已存在,并正确设置库路径。
7、编码问题
原因:字符编码不一致导致连接失败。
解决方案:统一使用UTF-8或其他一致的字符编码格式。
二、示例代码与解析
以下是一个简单的C语言连接MySQL数据库的示例代码,以及可能遇到的问题和解决方法:
#include <stdio.h>
#include <stdlib.h>
#include <mysql/mysql.h>
int main() {
MYSQL *conn;
MYSQL_RES *res;
MYSQL_ROW row;
const char *server = "localhost";
const char *user = "root";
const char *password = "your_password"; /* set me first */
const char *database = "testdb";
conn = mysql_init(NULL);
// 尝试连接数据库
if (!mysql_real_connect(conn, server, user, password, database, 0, NULL, 0)) {
fprintf(stderr, "%s
", mysql_error(conn));
exit(1);
}
// 执行查询
if (mysql_query(conn, "SELECT * FROM test_table")) {
fprintf(stderr, "%s
", mysql_error(conn));
exit(1);
}
res = mysql_use_result(conn);
// 输出结果集
printf("Results:
");
while ((row = mysql_fetch_row(res)) != NULL) {
printf("%s
", row[0]);
}
// 清理工作
mysql_free_result(res);
mysql_close(conn);
return 0;
} 可能遇到的问题及解决方法:
| 问题描述 | 可能原因 | 解决方法 |
| 编译错误:找不到mysql库 | 未安装MySQL开发库或库路径未配置 | 安装MySQL开发库并配置库路径 |
| 运行时错误:无法连接到数据库 | 数据库服务未启动或网络问题 | 检查数据库服务状态和网络连接 |
| 运行时错误:认证失败 | 用户名或密码错误 | 核对用户名和密码 |
| 运行时错误:SQL语法错误 | SQL查询语句有误 | 检查并修正SQL语句 |
三、FAQs(常见问题解答)
Q1: 如何检查MySQL服务是否已启动?
A1: 在Linux系统中,可以使用systemctl status mysql命令检查MySQL服务状态;在Windows系统中,可以通过服务管理器查看MySQL服务是否正在运行,如果服务未启动,可以使用systemctl start mysql(Linux)或通过服务管理器手动启动(Windows)。
Q2: 如果忘记了MySQL的root密码怎么办?
A2: 可以通过重置root密码来恢复访问权限,在Linux系统中,通常可以通过以下步骤重置密码:停止MySQL服务,使用--skip-grant-tables选项启动MySQL,然后登录MySQL并更新密码,最后重新启动MySQL服务,具体命令可能因操作系统而异,请参考官方文档进行操作。
小编有话说
数据库连接问题是开发过程中经常遇到的挑战之一,但通过仔细排查和逐一解决问题,大多数情况下都能找到解决方案,希望本文能帮助你更好地理解和解决C语言中数据库连接不上的问题,记得在遇到问题时保持耐心,逐步调试,相信你一定能够克服这些困难!







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11