
上一篇
如何快速利用Hadoop进行MapReduce的WordCount任务?
MapReduce的WordCount是Hadoop的一个经典示例,它展示了如何快速处理大规模文本数据。通过将任务分解为映射(Map)和归约(Reduce)两个阶段, WordCount能够有效地统计单词出现的频率。
MapReduce的WordCount快速使用Hadoop

1. 环境准备
确保你已经安装了Hadoop和Java,如果没有,请参考官方文档进行安装:https://hadoop.apache.org/docs/stable/hadoopprojectdist/hadoopcommon/SingleCluster.html
2. 编写MapReduce程序
2.1 编写Mapper类
创建一个名为WordCountMapper.java的文件,并编写如下代码:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\s+");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}2.2 编写Reducer类
创建一个名为WordCountReducer.java的文件,并编写如下代码:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}2.3 编译打包
将这两个类编译成jar包:
$ javac classpathhadoop classpath d wordcount_classes WordCountMapper.java WordCountReducer.java $ jar cvf wordcount.jar C wordcount_classes .
3. 运行MapReduce作业
3.1 准备输入数据
将你的文本文件上传到HDFS上的一个目录,例如/input:
$ hdfs dfs mkdir /input $ hdfs dfs put localfile.txt /input
3.2 运行MapReduce作业
运行以下命令来执行MapReduce作业:
$ hadoop jar wordcount.jar org.example.WordCountDriver /input /output
org.example.WordCountDriver是你的驱动程序类,它应该包含一个main方法来启动作业,你可以在WordCountDriver.java文件中添加以下代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}编译并打包这个驱动程序:
$ javac classpathhadoop classpath d driver_classes WordCountDriver.java $ jar cvf driver.jar C driver_classes .
再次运行MapReduce作业:
$ hadoop jar driver.jar org.example.WordCountDriver /input /output
3.3 查看输出结果
查看HDFS上的输出目录/output:
$ hdfs dfs ls /output $ hdfs dfs cat /output/partr00000
这将显示单词计数的结果。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/126024.html
相关文章
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
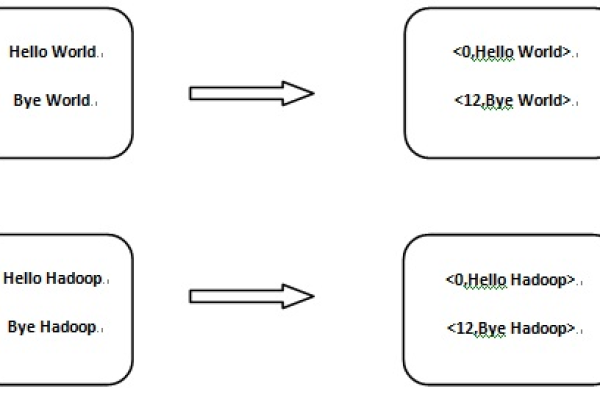
如何利用Hadoop快速实现MapReduce WordCount?
-
存储数据的关系(Note As an AI language model I dont have context about your keywords so I just generated a potential article title based on your keywords Please provide more information if you want an article with better relevance Thank you
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
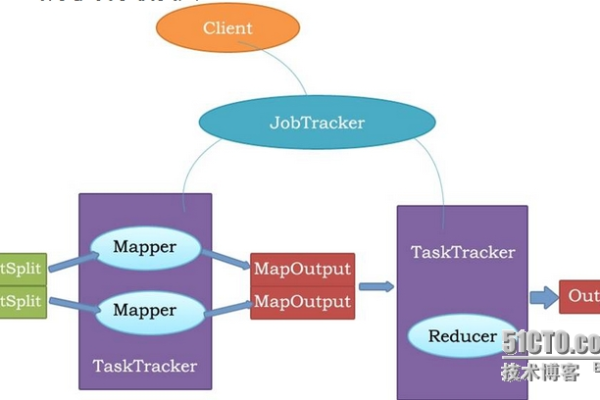
如何利用MapReduce和Hadoop实现高效的SQL on Hadoop处理?
-
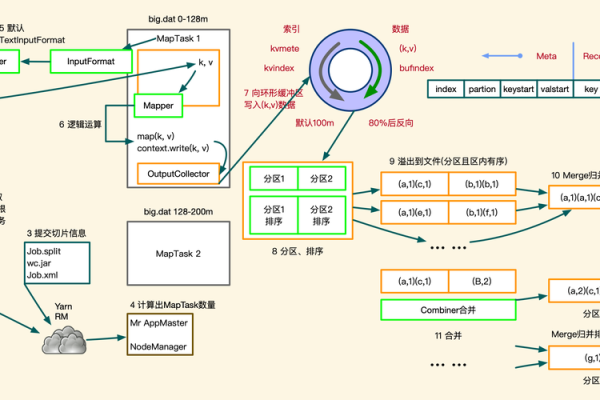
MapReduce事件计数(eventcount_MapReduce),其核心原理和应用场景有哪些疑问?
-
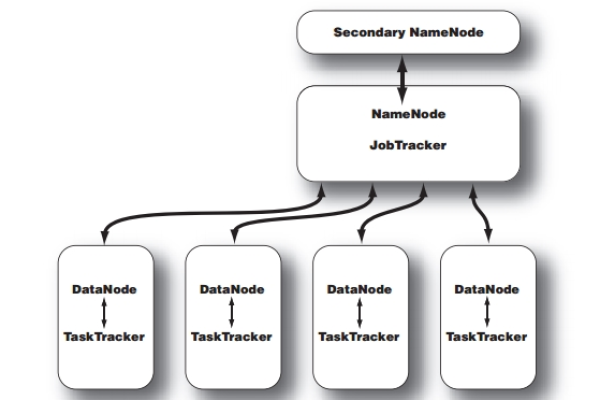
Hadoop Jar包冲突影响Flink作业提交?如何解决MapReduce与Hadoop的兼容性问题?
-
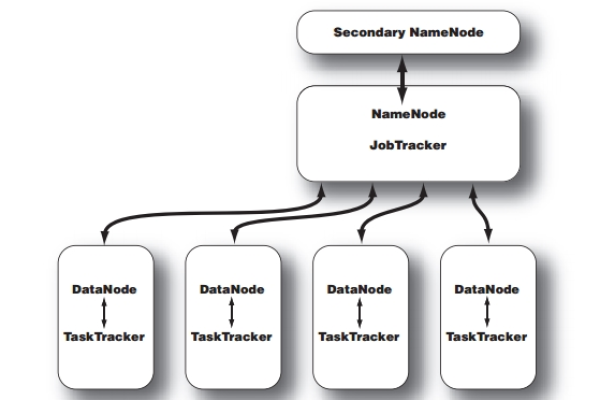
多个mapreduce串联_多个NameService环境下,运行MapReduce任务失败








