不用扫描仪 识别图片中的文字

可以使用OCR(光学字符识别)技术来识别图片中的文字。
在当今数字化时代,识别图片中的文字已成为一项常见需求,并非所有情况下都方便使用扫描仪来完成这一任务,幸运的是,有多种方法可以在不借助扫描仪的情况下,有效地识别图片中的文字。
| 方法 | 具体描述 | 适用场景 | 优缺点 |
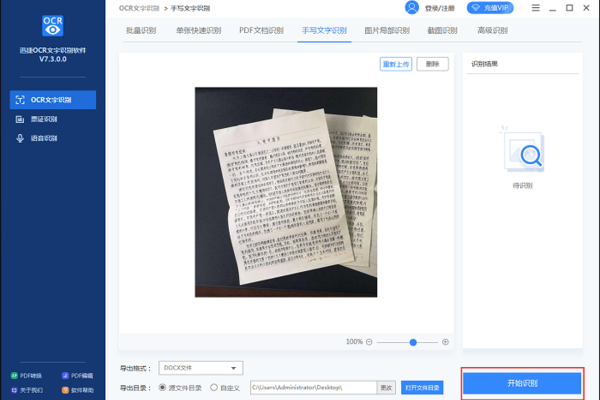
| 手机拍照识别 | 利用手机上的相机拍摄包含文字的图片,然后通过手机系统自带的文字识别功能(如 iOS 的 Live Text、安卓的 Google 文字识别等)或者安装专业的文字识别应用程序来提取文字信息。 | 适用于日常快速识别少量文字的场景,比如识别路牌、书籍中的短文本等。 | 优点:方便快捷,随时随地可操作;缺点:识别准确率可能受光线、拍摄角度等因素影响,对于复杂排版或低分辨率图片效果欠佳。 |
| 在线文字识别工具 | 将图片上传至提供文字识别服务的在线平台,这些平台通常基于先进的光学字符识别(OCR)技术,能够分析图片中的文字并返回可编辑的文本格式。 | 当需要处理一些不太紧急且对识别精度要求较高的任务时较为合适,例如识别文档中的文字内容用于存档或简单编辑。 | 优点:无需安装额外软件,通过浏览器即可使用;一些平台支持多种语言和字体识别,缺点:依赖网络连接,上传和下载图片可能会花费一定时间,且可能存在隐私泄露风险(如果平台安全性不佳)。 |
| 专业图像编辑软件 + 插件 | 先使用专业图像编辑软件(如 Adobe Photoshop 等)对图片进行预处理,如调整对比度、清晰度等,以提高文字的可辨识度,然后再结合相应的 OCR 插件(如 Tesseract 等)进行文字识别。 | 对于设计人员或对图像处理有较高要求的用户,在处理包含文字的图像设计稿等复杂情况时比较有用。 | 优点:可以精细控制图像预处理过程,提高识别成功率;缺点:学习成本较高,需要掌握专业软件的操作技巧,且插件的使用可能需要一定的配置和调试。 |
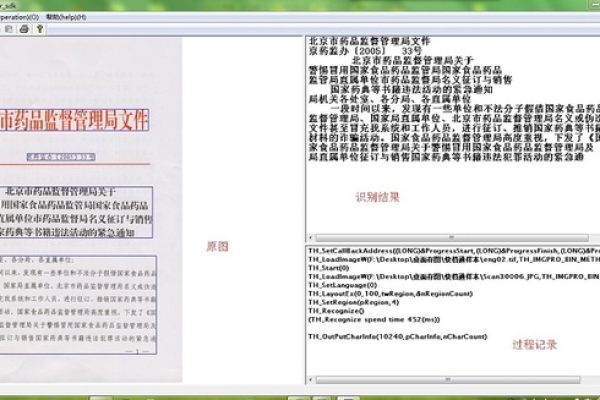
| 编程语言实现 OCR | 对于有一定编程基础的用户,可以使用 Python 等编程语言结合开源的 OCR 库(如 pytesseract)来编写自定义的文字识别脚本,通过代码读取本地图片文件,调用库函数进行文字识别,并将结果输出为文本文件或其他格式。 | 适合开发者进行批量文字识别任务或集成到其他自动化流程中,例如处理大量的图片文件并提取其中的文字信息用于数据分析。 | 优点:高度可定制,能够根据特定需求灵活调整识别参数和后处理逻辑;缺点:需要具备编程知识和相关开发环境,开发和维护成本相对较高。 |
以下是两个关于不用扫描仪识别图片中文字的常见问题及解答:
问题一:手机拍照识别文字时,如何提高识别准确率?
答:要提高手机拍照识别文字的准确率,可以从以下几个方面入手,确保拍摄环境的光线充足且均匀,避免阴影或反光影响文字的清晰度,保持手机与文字的适当距离和角度,尽量使文字在画面中清晰、端正且完整显示,部分手机系统的文字识别功能可能支持手动调整识别区域,你可以根据实际情况框选最需要识别的文字部分,减少背景干扰,如果使用的是第三方应用程序,还可以查看其设置选项,有些应用提供了增强对比度、锐化等图像预处理功能,合理使用这些功能有助于提升识别效果。
问题二:在线文字识别工具上传图片时,有哪些注意事项?
答:在使用在线文字识别工具上传图片时,需要注意以下几点,一是图片的格式,常见的如 JPEG、PNG 等格式一般是被广泛支持的,但某些平台可能对特定格式有偏好或限制,最好提前查看平台说明,二是图片的大小和分辨率,过大的图片可能会导致上传时间过长甚至上传失败,而过小或分辨率过低的图片可能会使文字模糊不清,影响识别效果,建议在保证文字清晰可辨的前提下,尽量控制图片大小适中,三是注意平台的隐私政策和数据安全措施,因为上传图片可能涉及个人敏感信息或重要数据,选择信誉良好、有安全保障的平台至关重要,避免因平台破绽导致信息泄露。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20