AI智能语音原理

AI智能语音原理
1、语音采集:通过麦克风等设备,将用户的语音转化为数字信号,这是语音交互的起点,为后续处理提供了基础。
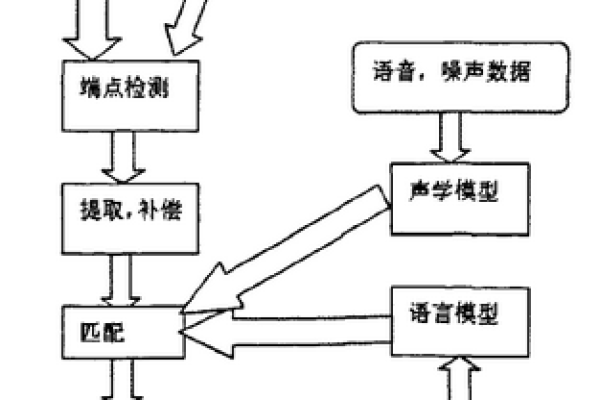
2、语音识别(ASR):利用自然语言处理技术,将数字信号转换为文本,这一过程涉及声学模型、语言模型和发音字典等复杂技术,旨在准确捕捉用户的语音信息,语音识别技术的核心是将人类语音转换为文字,其工作流程包括音频信号处理、特征提取、声学模型、语言模型和解码器等步骤。
3、意图理解:系统通过语义分析,理解用户的意图和需求,这一步骤是智能语音系统实现个性化服务的关键,在意图识别中,NLP模型识别用户语音中的意图,如查询天气或控制设备。

4、信息处理:根据用户的需求,系统进行数据检索、指令执行或生成相应的回复,这一步骤体现了系统的智能性和实用性。
5、语音合成(TTS):将生成的文本回应转化为自然的语音输出,它利用语音合成引擎生成逼真的语音,使机器能够以人类语音的方式与用户进行交互,这一技术使得对话更加逼真,增强了用户的交互体验,语音合成的基本流程包括文本分析、音素生成、声学模型和语音波形合成等步骤。

单元表格
| 步骤 | 描述 | 关键技术 |
| 语音采集 | 通过麦克风等设备,将用户的语音转化为数字信号。 | 麦克风阵列、移动设备 |
| 语音识别 | 利用自然语言处理技术,将数字信号转换为文本。 | 声学模型、语言模型、发音字典 |
| 意图理解 | 系统通过语义分析,理解用户的意图和需求。 | 语义分析、命名实体识别(NER) |
| 信息处理 | 根据用户的需求,系统进行数据检索、指令执行或生成相应的回复。 | 数据检索、指令执行 |
| 语音合成 | 将生成的文本回应转化为自然的语音输出。 | 语音合成引擎、情感语音合成技术 |
相关问题与解答
1、什么是语音识别技术中的声学模型?
解答:声学模型是语音识别技术中的一个关键组成部分,它用于将提取到的语音特征与音素或词的概率模型进行匹配,常用的声学模型包括深度神经网络(DNN)或循环神经网络(RNN),这些模型通过大量训练数据来学习语音信号与文本之间的映射关系,从而提高语音识别的准确性。

2、深度学习技术如何提升智能语音交互的准确性和流畅度?
解答:深度学习技术通过构建复杂的神经网络模型,如卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM),以及Transformer模型等,来自动提取语音信号中的特征,并进行模式匹配和预测,这些模型能够处理大量的训练数据,学习到语音信号中的复杂结构和模式,从而显著提升语音识别和语音合成的准确性,深度学习技术还能够实现端到端的训练,直接将输入音频映射到输出文本或语音,提高了系统集成性与训练效率。






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22