建造网站究竟需要多少钱?

在数字化时代,拥有一个网站对于企业和个人来说至关重要,它不仅是展示信息、提供服务的平台,更是与用户互动、建立品牌形象的重要途径,建造一个网站的成本因多种因素而异,包括网站的复杂性、功能需求、设计要求以及维护费用等,本文将详细探讨建造网站所需的各项费用,并提供一些实用的建议。
一、网站建设的基础费用
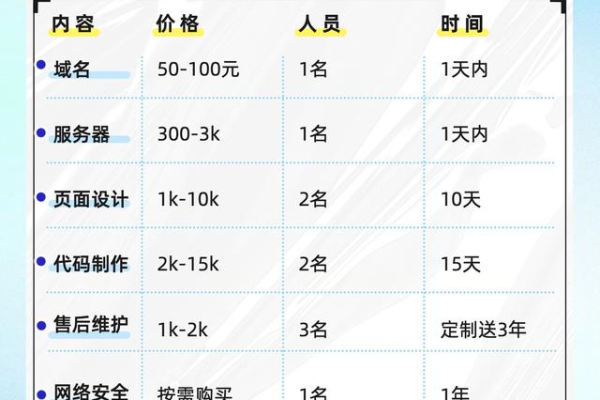
网站建设的基础费用主要包括域名注册、服务器托管(或购买)以及网站设计与开发的费用,以下是这些基础费用的大致范围:
1、域名注册:域名是网站的地址,通常需要每年支付一定的费用进行续费,价格根据域名的热门程度和后缀不同而有所差异,一般在几十元至几百元人民币不等。
2、服务器托管/购买:服务器是存放网站文件和数据的地方,对于小型网站,可以选择共享主机,费用相对较低,每年几百元至几千元不等;对于大型网站或需要高性能的网站,可能需要购买独立服务器或云服务器,费用会更高。
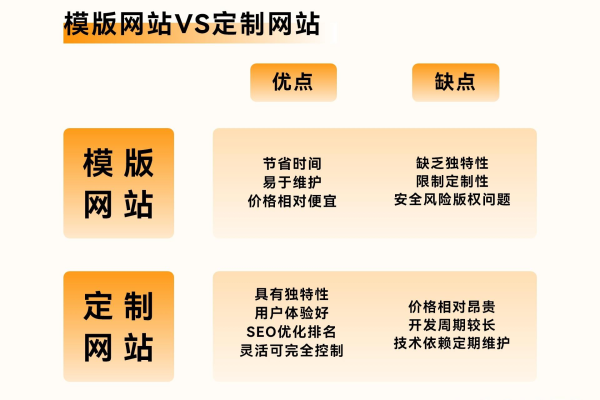
3、网站设计与开发:这是网站建设中最主要的费用部分,简单的静态网页设计可能只需要几千元,而包含复杂功能(如用户注册、购物车、支付系统等)的动态网站则需要几万元甚至更多,费用取决于设计师和开发人员的经验、技能以及项目的复杂度。
二、额外功能与定制开发
除了基础费用外,如果网站需要额外的功能或定制开发,还会产生额外的费用,以下是一些常见的额外功能及其大致费用范围:
1、内容管理系统(CMS):用于管理网站内容的系统,可以大大简化网站更新和维护的过程,一些流行的CMS平台(如WordPress、Joomla)是开源的,但定制开发或购买高级插件可能需要额外费用。

2、搜索引擎优化(SEO):为了提高网站在搜索引擎中的排名,可能需要进行SEO优化,这包括关键词研究、网站结构优化、内容优化等,SEO服务的费用因服务提供商和项目规模而异,一般从几千元至几万元不等。
3、多语言支持:如果网站需要支持多种语言,需要进行额外的翻译和本地化工作,费用取决于翻译的语种数量和网站的复杂度。
4、移动适配:随着移动设备的普及,确保网站在不同设备上都能良好显示变得尤为重要,移动适配可能需要额外的设计和开发工作,费用也会相应增加。
5、安全性增强:为了保护网站免受破解攻击和数据泄露,可能需要采取额外的安全措施,如安装SSL证书、定期备份、安全审计等,这些措施都会产生一定的费用。
三、维护与更新费用
网站建设完成后,还需要进行持续的维护和更新,以下是一些常见的维护与更新费用:

1、内容更新:定期更新网站内容以保持其时效性和吸引力,这可能包括撰写新文章、发布新闻、更新产品信息等,内容更新的频率和数量会影响维护费用。
2、技术维护:确保网站的正常运行和性能优化,这包括修复破绽、更新软件版本、优化数据库等,技术维护通常需要专业的技术人员进行操作。
3、备份与恢复:定期备份网站数据以防止数据丢失或损坏,也需要制定应急恢复计划以应对可能的故障或攻击,备份与恢复服务通常由服务提供商提供并收取一定费用。
4、客户服务与支持:为客户提供及时的技术支持和帮助解决他们在使用过程中遇到的问题,这可以通过电话、电子邮件或在线聊天等方式进行,客户服务与支持的质量直接影响用户体验和满意度因此也是维护费用中的一部分。
综上所述建造一个网站的成本因多种因素而异从几千元到几万元甚至更多都有可能具体取决于您的需求预算以及选择的服务提供商和服务内容为了控制成本并确保网站的质量建议您在开始建设之前仔细规划您的需求并咨询多家服务提供商以获取报价和比较服务质量同时不要忽视网站的持续维护和更新以确保其长期稳定运行并满足用户需求最后请注意在选择服务提供商时务必谨慎考虑其信誉度和专业能力以避免不必要的风险和损失。

五、FAQs
Q1: 建造一个网站需要多长时间?
A1: 建造一个网站的时间取决于多个因素,包括网站的复杂度、功能需求、设计要求以及开发团队的效率等,一个简单的静态网页可能只需要几天或几周的时间就能完成,而一个包含复杂功能和高度定制化需求的动态网站可能需要几个月甚至更长的时间来开发和测试,在开始建设之前,最好与开发团队详细讨论项目时间表并设定合理的期望值。
Q2: 如何选择合适的网站建设服务提供商?
A2: 选择合适的网站建设服务提供商需要考虑多个方面,要明确自己的需求和预算范围,以便找到与之相匹配的服务提供商,要查看服务提供商的案例和客户评价,了解他们的专业能力和服务质量,还可以考虑服务提供商的技术实力、团队规模、售后服务等因素,不要忽视与服务提供商的沟通和合作体验,确保双方能够顺畅地交流并共同推进项目进展。
到此,以上就是小编对于“建造网站多少钱”的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01