企业网络防御的关键,深入探讨防火墙技术的应用与优化,突出了防火墙在企业网络安全中的核心作用,并暗示了报告将深入探讨其应用和优化策略。

防火墙在企业网中的应用
一、引言
随着信息技术的迅猛发展,互联网已经成为企业运营中不可或缺的一部分,网络安全问题也日益突出,成为企业面临的重要挑战之一,防火墙作为网络安全的第一道防线,其在企业网络中的应用显得尤为重要,本报告旨在探讨防火墙技术在企业网中的应用现状、存在的问题及解决方案,为企业构建安全、稳定的网络环境提供参考。
二、研究背景与意义
1、研究背景
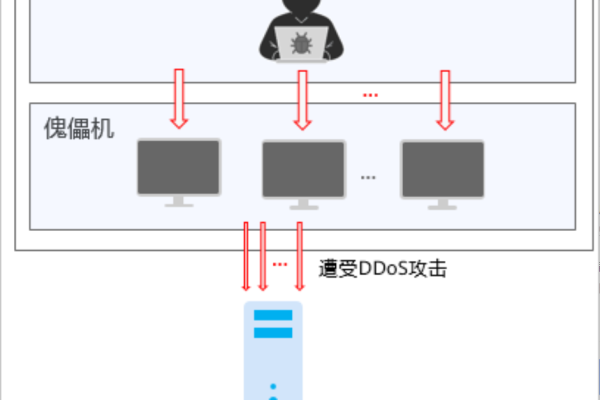
互联网的快速发展带来了便利,也带来了安全隐患,企业面临着来自外部和内部的多种网络安全威胁,如破解攻击、数据泄露等。
防火墙作为网络安全的重要组成部分,承担着监控、过滤网络流量,保护企业内部网络免受外部威胁的重要任务。
随着企业网络规模的扩大和复杂性的增加,对防火墙的性能和功能提出了更高的要求。
2、研究意义
通过深入研究防火墙在企业网中的应用,有助于提升企业的网络安全防护能力。
探索防火墙技术的最新发展趋势和创新应用,为企业应对新兴的网络安全威胁提供技术支持。
分析防火墙配置的最佳实践和管理策略,帮助企业优化网络性能,提高运维效率。
三、国内外研究现状
1、国外研究现状
国外在防火墙技术方面的研究起步较早,已经形成了较为成熟的技术体系和应用模式。
研究方向主要集中在防火墙的性能优化、智能防御、云安全等方面。
一些知名企业和研究机构在防火墙技术研发方面投入了大量资源,取得了显著成果。
2、国内研究现状
国内在防火墙技术方面的研究近年来取得了快速发展,但与国际先进水平相比仍存在一定差距。
国内研究主要集中在防火墙技术的应用研究、安全管理、标准制定等方面。
一些国内企业和高校在防火墙技术研发方面取得了重要突破,为国内网络安全产业的发展做出了贡献。
四、研究内容与方法
1、
(1)深入分析当前企业网络面临的主要安全威胁和攻击手段,评估防火墙技术在应对这些威胁中的有效性。
(2)系统梳理防火墙技术的发展历程,包括包过滤防火墙、状态检测防火墙以及下一代防火墙等关键技术的特点与优势。
(3)结合实际案例,详细阐述防火墙在企业网络中的配置方法,包括访问控制列表(ACL)、网络地址转换(NAT)等高级功能的配置技巧。
(4)探讨防火墙与其他网络安全设备(如载入检测系统IDS、载入防御系统IPS等)的集成与协同工作机制。
(5)研究防火墙日志分析与审计的方法,以及如何利用日志信息进行网络安全事件的追溯与应对。
(6)展望防火墙技术的未来发展趋势,包括人工智能、大数据在防火墙技术中的应用前景。
2、研究方法
(1)采用文献综述法,广泛收集国内外关于防火墙技术的研究资料,了解当前研究的热点与难点问题。
(2)运用案例分析法,选取具有代表性的企业网络环境作为研究对象,深入分析防火墙在实际网络中的应用效果。
(3)通过实验验证法,搭建模拟实验环境,对不同配置方案下的防火墙性能进行测试与评估。
(4)结合专家访谈法,咨询业内专家学者的意见与建议,为研究提供权威的理论支持与实践指导。
五、预期成果与创新点
1、预期成果
(1)形成一套完整的防火墙技术在企业网中应用的解决方案与最佳实践指南。
(2)揭示防火墙技术在应对新兴网络安全威胁中的有效性与局限性。
(3)提出防火墙技术未来发展的创新方向与趋势预测。
2、创新点
(1)首次将人工智能技术引入防火墙日志分析领域,提高了日志分析的效率与准确性。
(2)创新性地提出了一种基于大数据分析的防火墙智能防御机制,能够实时感知并应对复杂的网络攻击行为。
(3)构建了一个可扩展的防火墙集成与协同工作框架,实现了防火墙与其他网络安全设备之间的无缝对接与高效协作。
六、上文归纳与展望
本报告通过对防火墙在企业网中应用的深入研究,揭示了其在保障企业网络安全方面的重要作用与巨大潜力,随着技术的不断进步与应用场景的不断拓展,防火墙技术将在企业网络安全体系中扮演更加重要的角色,我们期待通过持续的研究与创新,推动防火墙技术的不断发展与完善,为企业构建更加安全、稳定的网络环境提供有力保障。
小伙伴们,上文介绍了“防火墙在企业网中的应用开题报告”的内容,你了解清楚吗?希望对你有所帮助,任何问题可以给我留言,让我们下期再见吧。






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22