
上一篇
MapReduce JobHistoryServer 堆内存使用率过高,ALM18009 问题在旧版本中如何诊断和解决?
MapReduce实例_ALM18009涉及JobHistoryServer在2.x及更早版本中堆内存使用率过高的问题。这可能导致性能下降和稳定性问题,需要监控并采取措施优化内存使用或升级系统以解决此问题。
MapReduce JobHistoryServer堆内存使用率超过阈值(2.x及以前版本)

问题描述
在MapReduce的JobHistoryServer中,如果堆内存使用率超过了设定的阈值,可能会导致性能下降或系统不稳定,这种情况通常发生在较旧版本的Hadoop(2.x及以前版本)。
原因分析
1、内存泄漏:应用程序中可能存在内存泄漏,导致堆内存不断增长。
2、配置不当:JobHistoryServer的配置可能不适合当前的硬件环境和工作负载。
3、资源限制:服务器上的物理内存不足,导致JobHistoryServer无法获取足够的内存来满足需求。
解决方案
步骤1:检查内存泄漏
需要检查是否存在内存泄漏,可以使用Java的内存分析工具(如VisualVM、MAT等)来分析JobHistoryServer的堆内存快照,找出潜在的内存泄漏点。
步骤2:调整配置参数
根据分析结果,可以尝试调整JobHistoryServer的配置参数,例如增加堆内存大小或调整垃圾回收策略,可以在mapredsite.xml文件中设置以下参数:
<property> <name>mapreduce.jobhistory.webapp.heapsize</name> <value>512m</value> </property> <property> <name>mapreduce.jobhistory.admin.heapsize</name> <value>512m</value> </property>
步骤3:优化资源分配
如果调整配置参数后问题仍然存在,可以考虑优化资源分配,这可能包括增加服务器的物理内存、升级硬件或调整集群的其他组件以减轻JobHistoryServer的负担。
通过以上步骤,可以解决MapReduce JobHistoryServer堆内存使用率超过阈值的问题,在实际操作中,需要根据具体情况进行分析和调整,以达到最佳性能和稳定性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/125092.html
相关文章
-
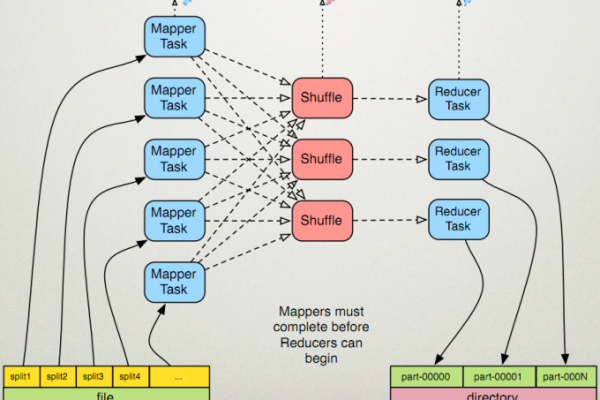
如何解决ALM18009 MapReduce JobHistoryServer堆内存使用率超过阈值的问题?
-
堆内存使用量波动大_ALM26054 Storm Nimbus堆内存使用率超过阈值(2.x及以前版本)
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
ALM26054 Nimbus堆内存使用率超过阈值,我们如何优化堆内存管理?
-

processes_镜像保存时报错“there are processes in 'D' status, please check process status using 'ps aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
-
kill mapreduce job_配置MapReduce Job基线
-

云服务器cpu使用率过高怎么解决「云服务器cpu使用率过高怎么解决」
-

Unveiling the Mystery of UE4CDN: Whats Behind This Enigmatic Abbreviation?,这个疑问句标题旨在吸引那些对UE4CDN这一缩写词或其背后概念感到好奇的读者。通过使用Unveiling the Mystery和Whats Behind This Enigmatic Abbreviation?这样的短语,标题传达了探索和揭示未知信息的意图,激发读者的好奇心,促使他们点击阅读以获取更多信息。








