如何有效管理和部署系统补丁以提升网络安全?

系统补丁是计算机操作系统中不可或缺的一部分,它们的主要作用是修复破绽、提升性能和增强系统安全性,在信息技术飞速发展的今天,系统补丁的重要性愈发突出,本文将详细探讨系统补丁的定义、类型、重要性、安装方法以及常见问题。
一、什么是系统补丁?
系统补丁(System Patch)是由软件开发商发布的一段代码或一组文件,用于修复软件中的缺陷、破绽或错误,这些补丁通常以更新包的形式发布,用户可以通过下载并安装这些更新来改进其软件的功能和安全性。
二、系统补丁的类型
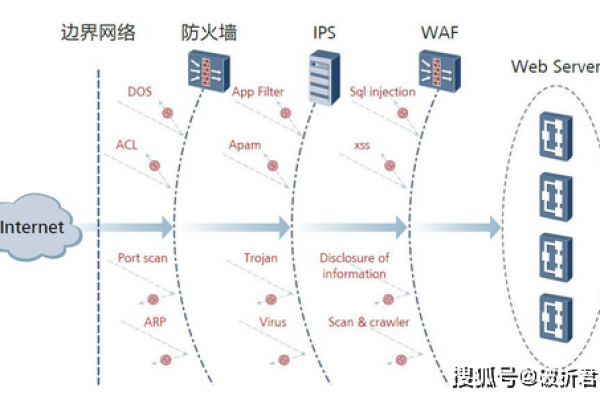
1、安全补丁:主要用于修复系统中的安全破绽,防止破解攻击和反面软件载入。
2、功能补丁:用于增加新功能或改进现有功能,使系统更加完善和易用。
3、性能补丁:旨在提高系统的运行效率,减少资源消耗,提高响应速度。
4、兼容性补丁:用于解决系统与新硬件或新软件之间的兼容问题。
三、系统补丁的重要性
提升安全性:安全补丁能够及时修补系统中的破绽,防止被反面利用,保护用户数据安全。
改善性能:性能补丁可以优化系统资源的使用,提高整体运行效率。
增强稳定性:功能补丁和兼容性补丁能够解决软件中的各种bug,提高系统的稳定性和可靠性。
延长寿命:通过定期安装补丁,可以使老旧系统继续保持良好的运行状态,延长其使用寿命。
四、如何安装系统补丁?
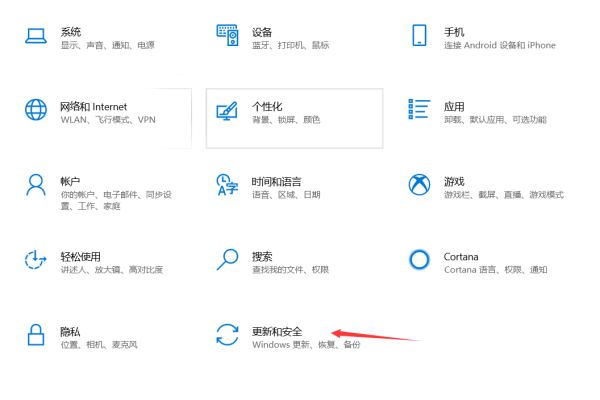
1. 自动更新
大多数现代操作系统都提供了自动更新功能,用户可以在设置中开启此功能,让系统自动检测并安装最新的补丁。
2. 手动更新
如果自动更新未开启或无法正常工作,用户也可以访问操作系统官方网站,手动下载并安装补丁,具体步骤如下:
访问操作系统官方网站的支持页面。
根据操作系统版本和类型选择相应的补丁下载链接。
下载完成后,按照提示进行安装。
重启计算机以确保补丁生效。
3. 第三方工具
除了官方提供的更新方式外,还有一些第三方工具可以帮助用户管理和安装系统补丁,例如各种安全软件自带的补丁管理功能。
五、常见问题解答(FAQs)
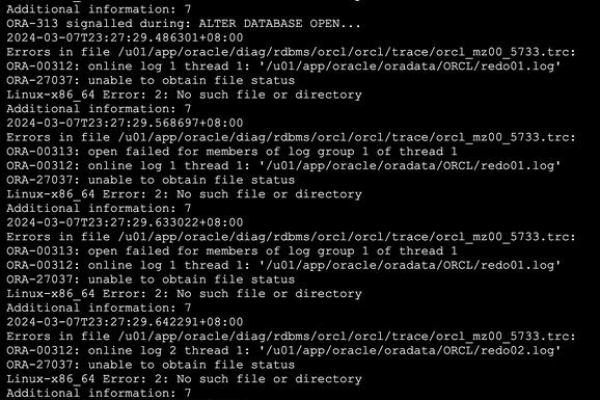
Q1: 为什么有时候安装了补丁后系统会出现问题?
A1: 这种情况通常是由于以下几个原因造成的:
不兼容:某些补丁可能与现有的硬件或软件存在不兼容的情况,导致系统不稳定。
安装不当:如果在安装过程中出现错误,可能会导致系统文件损坏或其他问题。
冲突:多个补丁之间可能存在冲突,特别是当它们试图修改同一个系统文件时。
残留文件:旧版本的文件没有完全删除干净,可能会影响新版本的正常运行。
为了避免这些问题,建议在安装补丁前备份重要数据,并确保从官方渠道下载补丁,安装前最好关闭不必要的程序和服务,减少干扰。
Q2: 如何检查是否所有必要的补丁都已安装?
A2: 要检查是否所有必要的补丁都已安装,可以采取以下几种方法:
查看更新历史记录:大多数操作系统都会记录已安装的更新历史,用户可以通过控制面板或设置菜单查看详细信息。
使用第三方工具:有些专门的软件可以帮助用户扫描系统,检查是否有遗漏的补丁,并提供一键安装功能。
官方支持网站:访问操作系统的官方网站,查看最新的补丁列表,并与自己系统中的版本对比,确认是否还有未安装的补丁。
定期检查并安装系统补丁是维护计算机健康的重要措施之一,通过上述方法,用户可以有效地管理和更新自己的系统,确保其安全性和稳定性。
各位小伙伴们,我刚刚为大家分享了有关“系统补丁”的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/124848.html