上一篇
服务器云储存还是实体机_数据转发至Kafka储存
服务器云存储与实体机的选择取决于数据安全、成本和可伸缩性需求。将数据转发至Kafka进行存储,可以高效处理实时数据流,支持高并发和大数据量处理,适用于需要快速数据处理和分析的场景。
在当今时代,数据的存储和处理变得越来越重要,尤其是对于大数据和实时数据处理的需求日益增长,Kafka作为一种高吞吐量的分布式消息系统,非常适合处理如数据转发和存储等任务,本文将探讨使用服务器云存储与实体机存储的数据通过规则引擎转发至Kafka进行储存的过程,并分析其实现方式,以下是一些核心步骤和概念的详细解析:

1、设备接入与数据转发设置
创建产品模型和注册设备:在设备接入服务中,首先需要创建相应的产品模型并注册设备,这一步是确立数据来源和数据格式的关键步骤,确保后续数据处理的准确性和一致性。
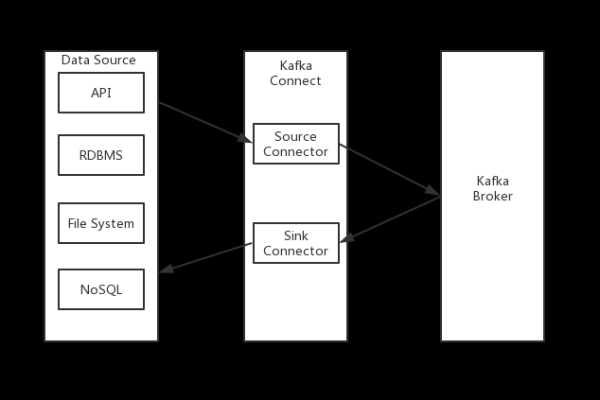
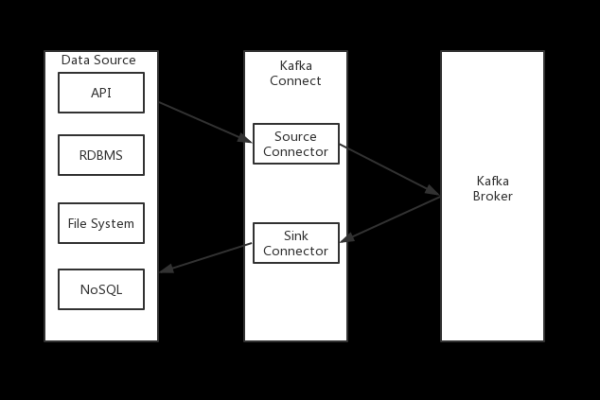
设置数据转发规则:通过设备接入服务,用户可以设置数据转发规则,实现当设备上报数据时,数据可以被自动转发至Kafka,这一过程涉及到规则的创建、目标设置以及规则的激活。
2、选择Kafka作为存储方案
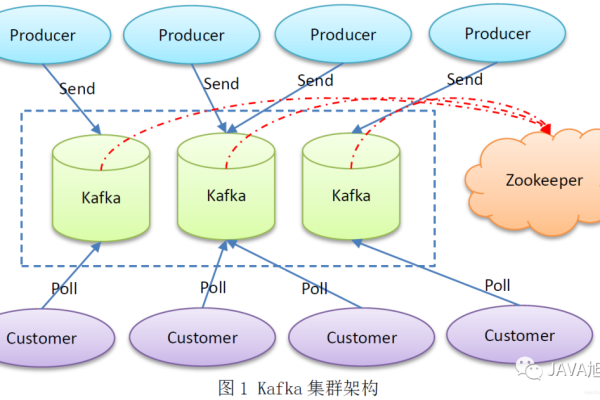
高性能的选择:Kafka以其优异的I/O性能而被选用,尤其是在处理大量写入操作时,其通过顺序批量写入的方式显著提高了写入速度。
适合大数据流处理:Kafka特别适合于处理海量数据流,这对于现代应用中常见的数据流处理需求来说,是一个理想的选择。
3、云服务器存储与实体机存储
云服务器的优势:采用分布式存储技术的云服务器可以提供更高的数据可靠性和安全性,数据多份复制并存储在不同的服务器上,极大地减少了由于硬件故障导致的数据丢失风险。
实体机的角色:实体机通常用于本地网络环境或私有云部署,其实体性质使得数据访问速度可能更快,但需要更多的物理空间和维护成本。
4、全链路数据传输的可靠性
利用规则引擎:规则引擎在此过程中扮演着重要的角色,它能够将物联网平台的数据高效转发到Kafka消息队列中,这不仅实现了数据的快速移动,还确保了整个传输链路的高可靠性。
无论是选择基于云的服务器存储还是实体机存储,通过合理配置和利用高效的数据转发机制,都可以实现数据的有效管理和安全储存,在实施类似项目时,考虑数据的类型、使用场景及成本效益比是非常关键的。
下面是一个简单的介绍,对比了使用服务器云存储与实体机将数据转发至Kafka储存的不同方面:
| 特性/组件 | 服务器云存储 | 实体机 |
| 部署方式 | 云服务提供商提供,可快速部署 | 自行购买硬件,需手动部署 |
| 扩展性 | 水平扩展容易,根据需求动态调整资源 | 扩展需要购买额外硬件,可能涉及停机时间 |
| 维护 | 云服务提供商负责硬件维护 | 自行负责硬件维护 |
| 成本 | 按需付费,无需大量前期投资 | 需要前期硬件投资,长期可能成本较低 |
| 可靠性 | 多可用区域,高可靠性 | 取决于硬件配置和冗余策略 |
| 性能 | 受网络带宽和云服务限制 | 通常更高,不受外部网络限制 |
| 数据传输至Kafka | 可以通过云服务提供的网络连接 | 需要内部网络配置,可能涉及安全组和防火墙设置 |
| 网络 | 受云服务网络环境影响 | 自定义网络配置,可以根据需要优化 |
| 安全 | 提供商通常提供多种安全措施 | 需要自行实施安全策略 |
| 故障恢复 | 自动化恢复机制 | 需要手动或半自动化恢复 |
| 自定义配置 | 受限,但云服务提供多种配置选项 | 完全自定义,灵活性高 |
| 数据持久性 | 通常与Kafka设置一致,取决于云服务提供商 | 与Kafka配置和实体机存储策略相关 |
| 数据备份 | 云服务提供备份解决方案 | 需要自行实施备份策略 |
请注意,介绍中的内容是基于一般情况的对比,具体情况可能根据不同的云服务提供商、实体机的配置以及实际业务需求有所差异,在选择方案时,应该根据实际的业务场景、预算、技术能力和数据安全要求来综合考虑。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/123485.html