学生机如何有效利用CDN加速网络访问?

学生机套CDN是一种通过将静态资源(如图片、视频、软件包等)存储在对象存储服务(OBS)中,并利用内容分发网络(CDN)加速这些资源的访问速度的方法,这种方案不仅能够提升网站的加载速度,还能节省服务器带宽成本,以下是详细解答:
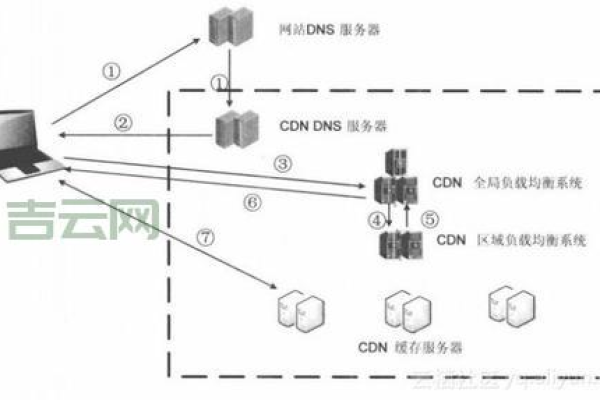
学生机套CDN的实现步骤
1、创建对象存储桶:首先需要在云服务提供商处创建一个对象存储桶(OBS),用于存放需要加速的静态资源文件。
2、绑定自定义域名:在对象存储控制台进行域名管理,绑定新的用户域名,并将该域名的CNAME记录指向对象存储桶的默认域名。
3、配置域名解析:在域名服务商处添加CNAME解析记录,将自定义域名指向对象存储桶的CNAME地址。
4、安装插件:如果是使用WordPress等建站工具,可以通过安装对应的对象存储插件来同步网站中的静态资源到OBS。
5、启用CDN加速:在CDN管理控制台中添加加速域名,并将源站类型设置为对象存储服务,选择之前创建的对象存储桶作为源站。
6、缓存刷新与预热:根据需要,可以对CDN节点进行缓存刷新或预热操作,以确保最新的资源被及时分发到各个节点。
表格展示
| 步骤 | 描述 | 示例 |
| 创建对象存储桶 | 在云服务提供商处创建一个对象存储桶 | OBS桶名称为my-obs-bucket |
| 绑定自定义域名 | 在对象存储控制台绑定新的用户域名 | 自定义域名为cdn.example.com |
| 配置域名解析 | 在域名服务商处添加CNAME解析记录 | CNAME指向cdn.example.com |
| 安装插件 | 安装对象存储插件并同步静态资源 | WordPress插件如HuaweiCloud OBS |
| 启用CDN加速 | 在CDN管理控制台添加加速域名 | 加速域名为cdn.example.com,源站为my-obs-bucket |
| 缓存刷新与预热 | 根据需要进行缓存刷新或预热操作 | 使用API接口进行缓存刷新 |
常见问题解答(FAQs)
Q1: CDN是否可以看到单个加速域名的计费情况?
A1: CDN计费是以租户为单位进行的,不支持查看单个加速域名的具体计费情况,如果需要了解域名的流量或带宽使用情况,可以在统计分析列表中查看相关数据。
Q2: CDN支持内网加速吗?
A2: CDN不支持内网加速,CDN加速需要通过DNS解析将域名的访问转发到节点,而内网域名无法完成这种配置。
小编有话说
通过学生机套CDN的方式,不仅可以显著提升网站的访问速度和用户体验,还能有效降低服务器的带宽成本,对于学生和小型网站来说,这是一种非常经济且高效的解决方案,希望以上内容能够帮助大家更好地理解和实施学生机套CDN的方法,如果有更多问题或需要进一步的帮助,欢迎随时提问!




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22